

Speaker emotion perception method fusing multi-dimensional information
A multi-dimensional information and emotion perception technology, applied in the field of deep learning and human emotion perception, can solve the problems of lack of speaker image information, inability to eliminate ambiguity, limited improvement effect, etc., to achieve elimination of ambiguity, good economic benefits, The effect of enhancing the fusion ability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0020] The present invention will be further explained below in conjunction with specific embodiments.
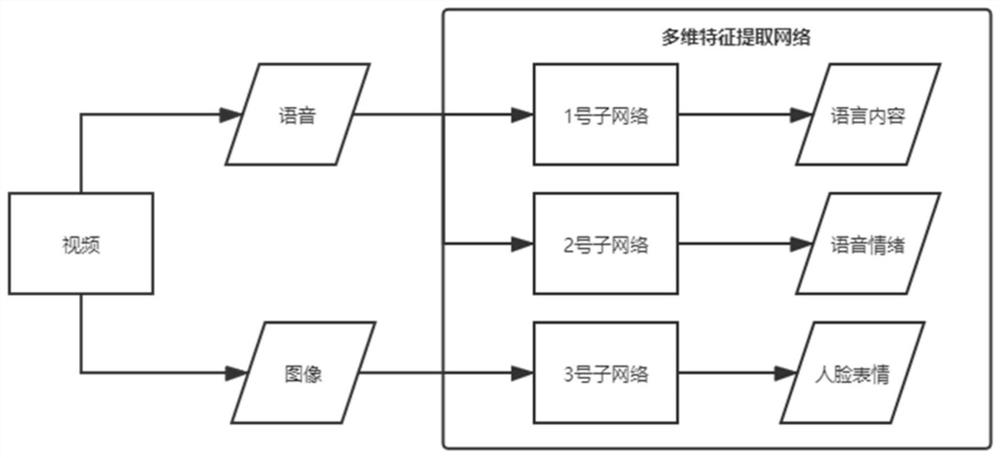
[0021] refer to Figure 1~3 , this embodiment proposes a speaker emotion perception method that fuses multi-dimensional information, including the following steps:
[0022] S1: Input the video of the speaker, and extract the image and voice of the speaker from the video;
[0023] S2: Input the speaker's image and voice into the multi-dimensional feature extraction network, and analyze the language content feature in the voice text and language emotion feature audio Extract and extract the speaker's facial expression feature feature from the image information face ;
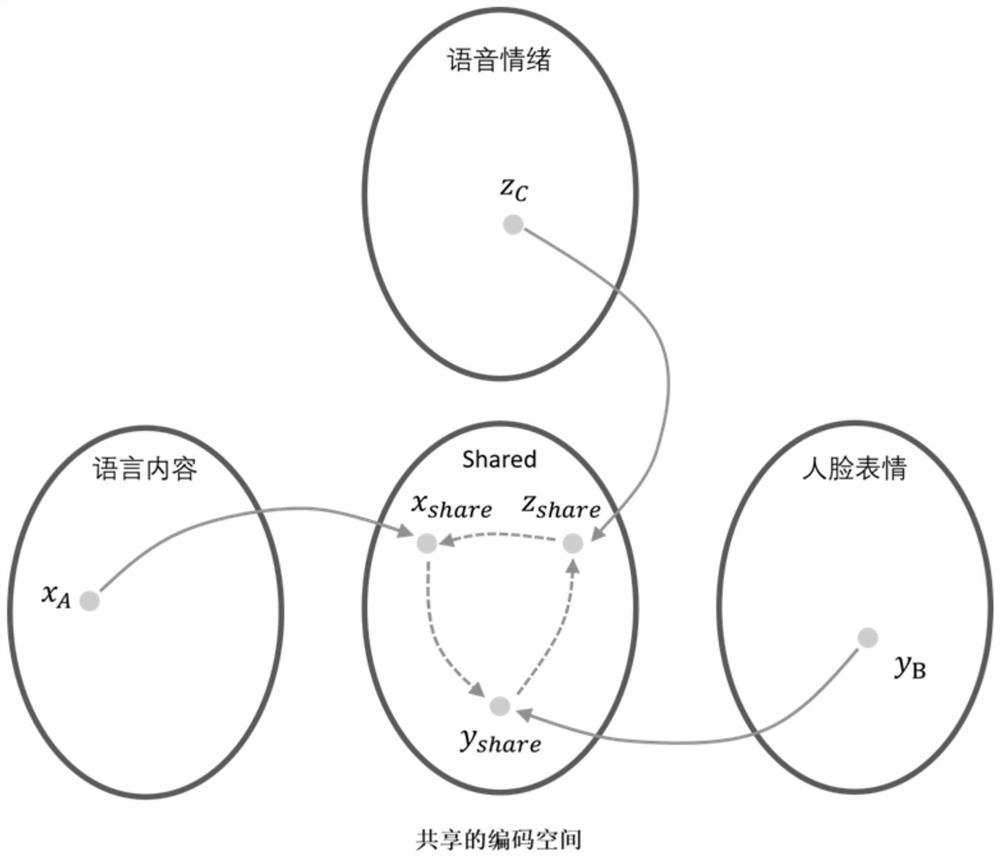
[0024] S3: Use the multi-dimensional feature encoding algorithm to encode the various feature results of the multi-dimensional feature extraction network, and map the multi-dimensional information to a shared encoding space Shared-Space(feature text ,fea ure audio ,feature face );
[0025] S4: Using a ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More