

Dynamic epsilone deep reinforcement learning method based on epsilone-greedy
A reinforcement learning, deep technique used in neural learning methods, machine learning, coinless or similar appliances
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment
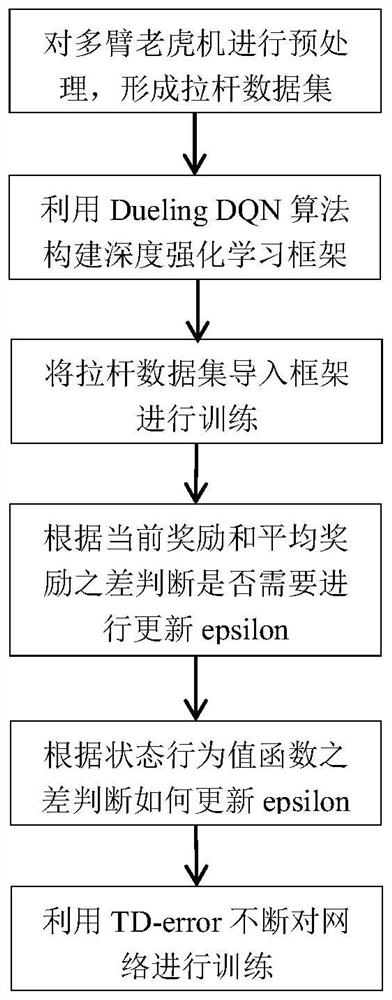
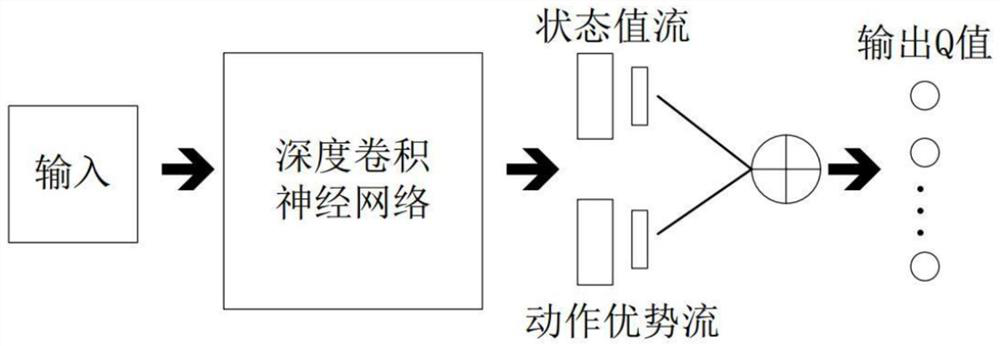
[0064] The simulation experiment was carried out under the python3.8 version, and the tensorflow version 2.3 framework was used, and the information of the multi-arm gambling machine was defined in the class, including the number of drawbars and the income brought by each drawbar; then tensorflow was used to build Dueling DQN algorithm deep reinforcement learning framework, input the obtained state set to Dueling DQN, and the obtained Q value is the sum of the state function value and the advantage function value. According to the TD-error of the behavior value function, it is judged whether to explore or use at this time. and update the value of epsilon.
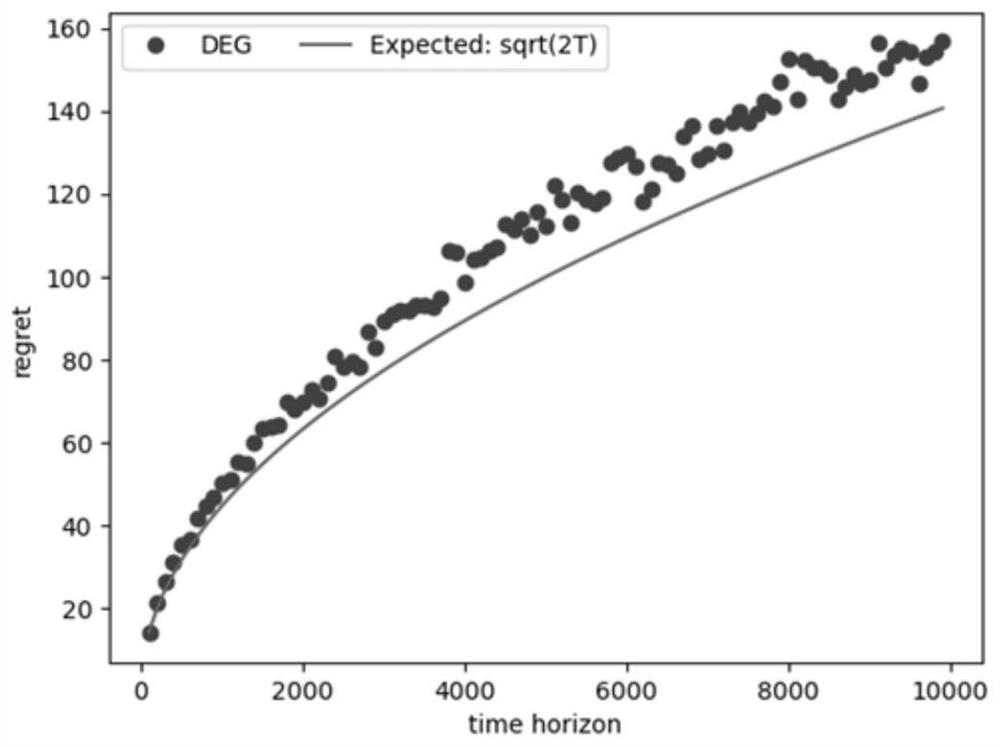
[0065] like image 3 shown, this is the final result, where DEG is the abbreviation of the algorithm of the present invention, the full name is DynamicEpsilon Greedy; the solid line represents the expectation curve, the horizontal axis represents how much time has passed, and the vertical axis represents the regret rate. ;...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More