

Task training method and device, equipment and storage medium
A training method and task technology, applied in the direction of program control device, program control design, instrument, etc., can solve the problems of inability to guarantee the normal operation of training tasks, waste of resources, etc., achieve the effect of realizing high-performance network card multiplexing and improving training efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
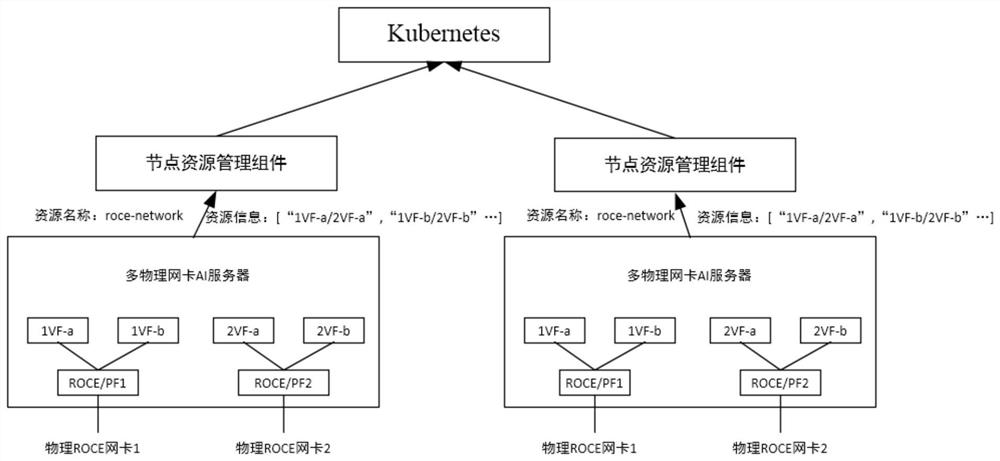
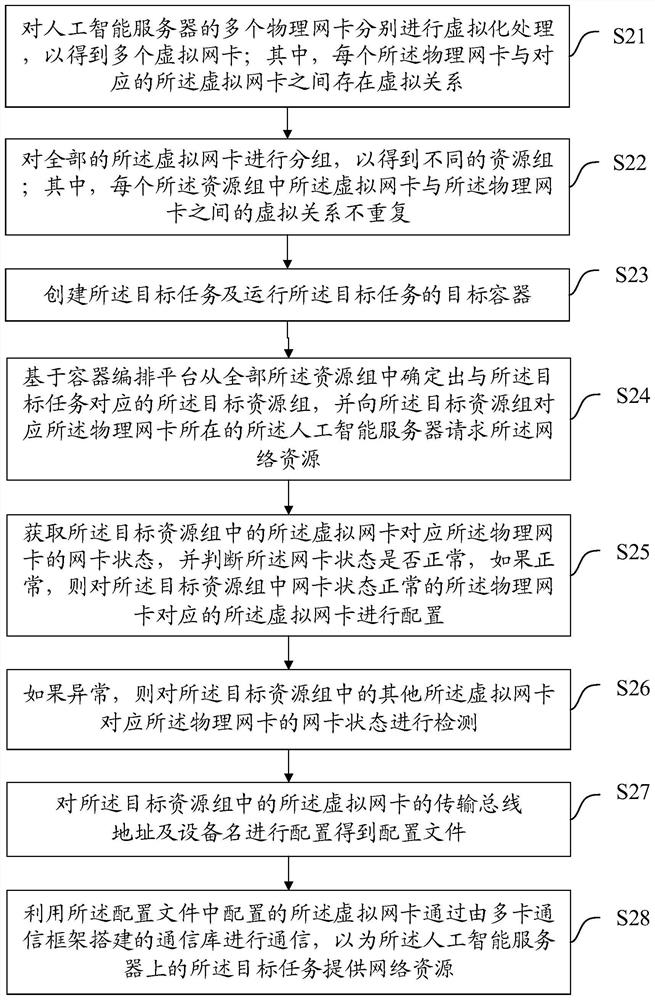
[0040] The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, but not all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
[0041] In the prior art, the Roce NIC and Infiniband NIC in the AI server cannot be bonded and resources are wasted. Generally, two high-performance NICs are not bonded. When the high-performance NIC is abnormal, the normal operation of the training task cannot be guaranteed. In view of the above-mentioned technical defects, the present application provides a task training scheme, which can reasonably allocate high-performance networ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More