

Wargame multi-entity asynchronous collaborative decision-making method and device based on reinforcement learning
A technology of reinforcement learning and collaborative decision-making, applied in neural learning methods, machine learning, biological models, etc., can solve problems such as difficult to effectively solve multi-entity asynchronous cooperation in war chess, inconsistent execution time of basic actions, etc. The effect of high combat efficiency and high final win rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
[0045] In order to make the purpose, technical solutions and advantages of the present application more clearly understood, the present application will be described in further detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are only used to explain the present application, but not to limit the present application.
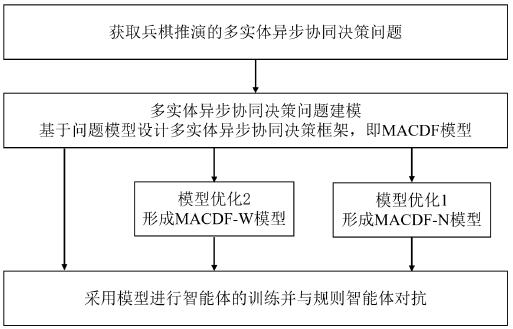
[0046] like figure 1 As shown, a reinforcement learning-based multi-entity asynchronous collaborative decision-making method for war chess provided by this application, in one embodiment, includes the following steps:
[0047] Step 102: Obtain a wargame environment and a multi-entity asynchronous cooperative decision-making problem corresponding to the wargame environment, and perform modeling and analysis on the multi-entity asynchronous cooperative decision-making problem to obtain an initial model.
[0048] Specifically, the wargame environment and the multi-entity...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More