

Systems and methods for identifying and extracting data from HTML pages
a technology of html pages and data extraction, applied in the field of analyzing and extracting information from web pages, can solve the problems of difficult computer programs to do so without knowing in advance which pieces to use, page complexity and variable, and may not be much more complex and variable. achieve the effect of quick extraction
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

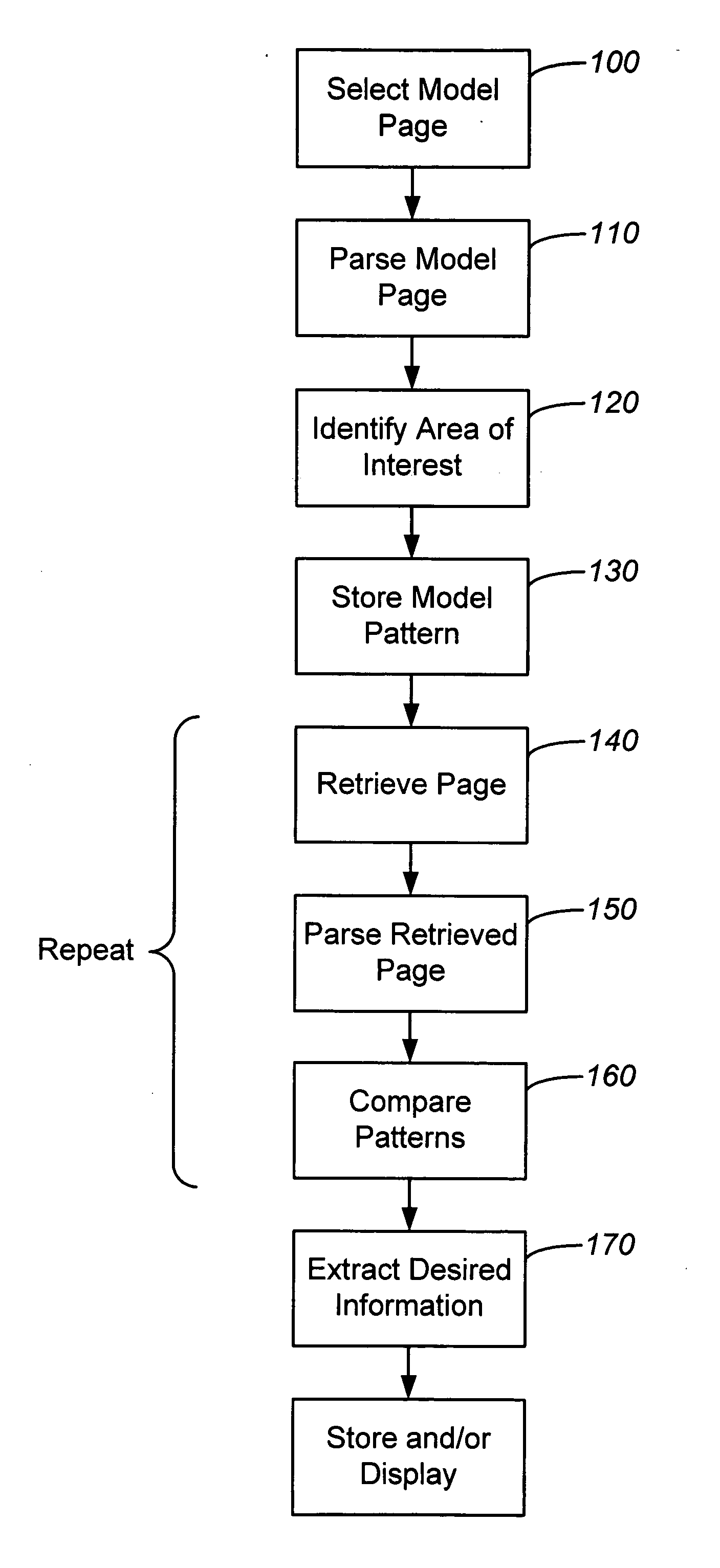
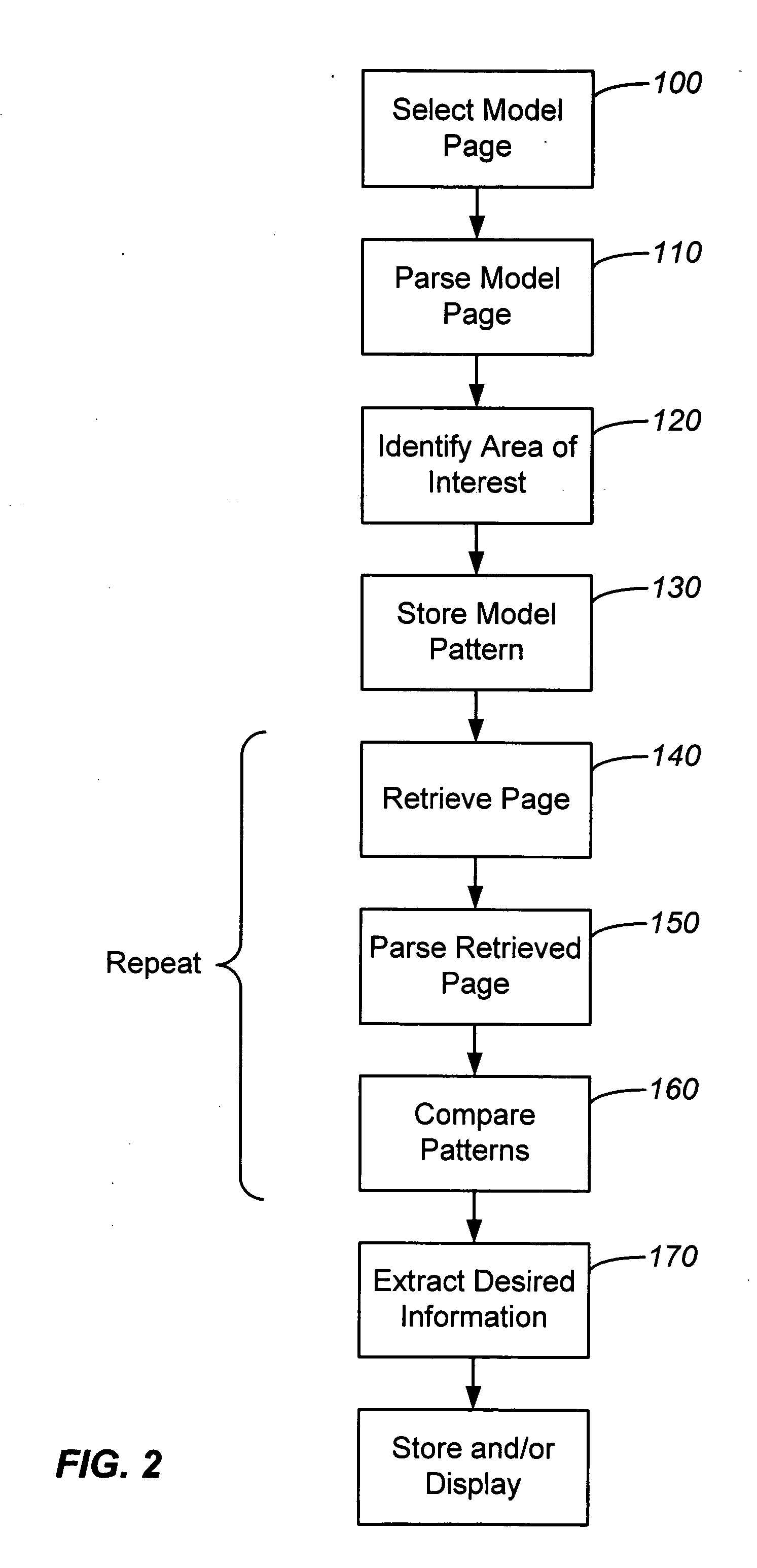
Examples
Embodiment Construction
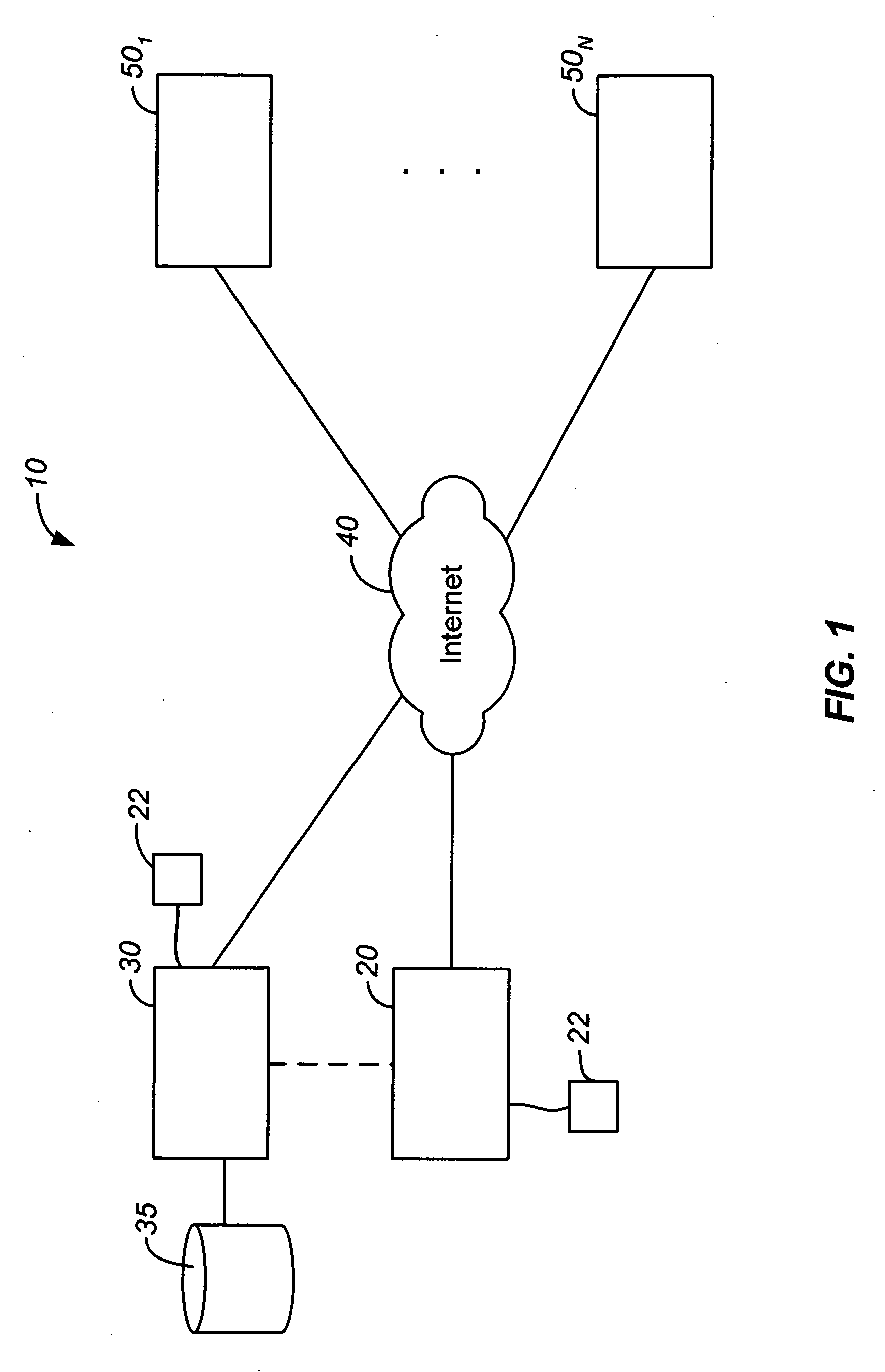
[0039]FIG. 1 illustrates a general overview of an information retrieval and communication network 10 including a client device 20 according to an embodiment of the present invention. In computer network 10, client device 20 is coupled through the Internet 40, or other communication network, to servers 501 to 50N. Client device 20 is also interconnected to server 30 either directly, over any LAN or WAN connection, or over the Internet 40. As will be described herein, client device 20 is configured according to the present invention to access and retrieve web pages from any of servers 501 to 50N, identify and extract desired information therefrom, and provide the information to server 30 to populate database 35. Although as described herein, access and processing of web pages is performed using client device 20, it will be understood that server 30 can also be configured to access and process web pages according to the present invention described herein.
[0040] Several elements in the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More