

User preference based data cleaning method
A technology of data cleaning and user data area, applied in neural learning methods, electrical digital data processing, special data processing applications, etc., can solve problems such as inability to effectively distinguish user-specific data, and achieve integrity and security Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
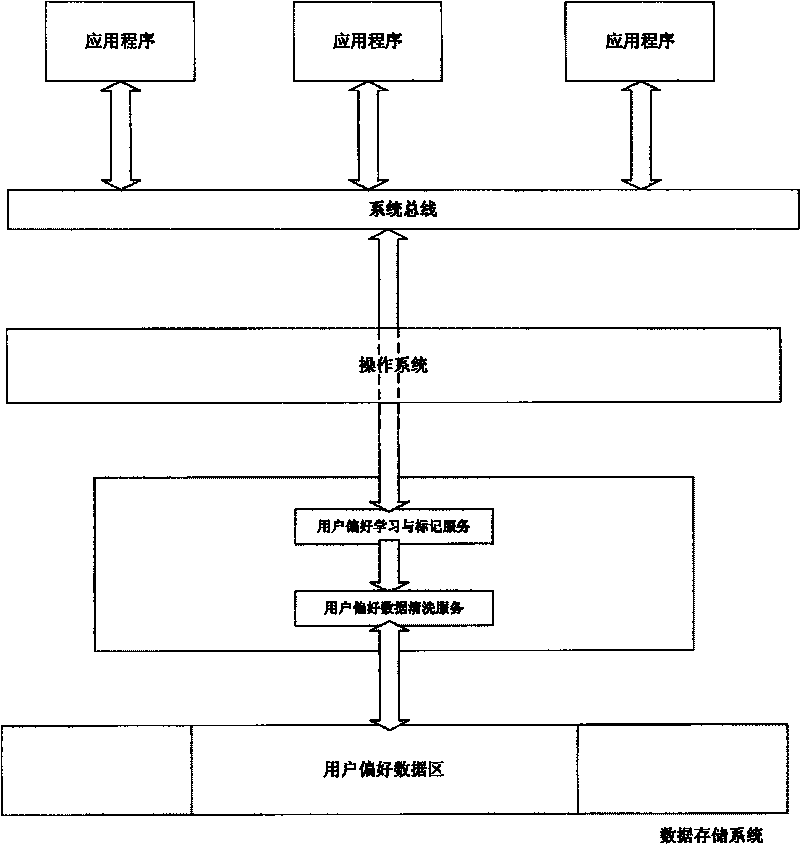
[0017] System architecture such as figure 1 as shown.
[0018] 1. User preference learning and labeling system
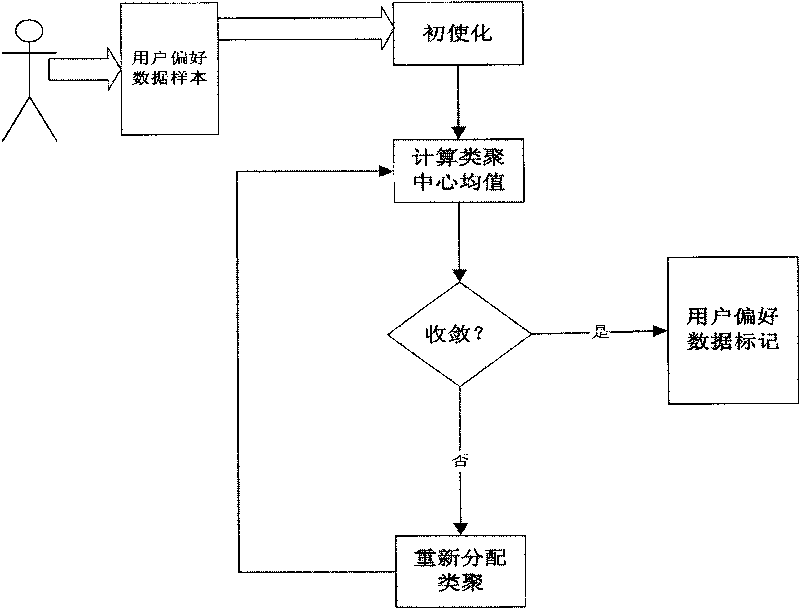
[0019] The user preference learning and marking system uses the K-means fuzzy clustering analysis neural network algorithm to realize the learning and memory of user behavior, and uses a large amount of user behavior data as sample data for training to complete the identification of user preferences and mark the preference data.
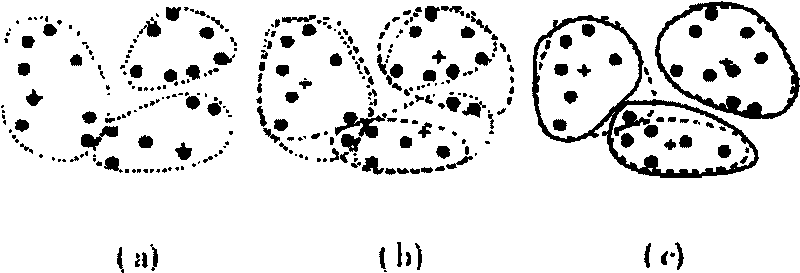
[0020] The K-means algorithm belongs to a kind of cluster analysis, which is to divide a group of physical or abstract objects into several groups according to the degree of similarity between them; among them, similar objects form a group, and this process is called clustering process. That is, searching for valuable connections between data items from a given data set. In many applications, all objects in a cluster are often treated or analyzed as one object:
[0021] (1) Input: the number of clusters k, and a database containing n d...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More