

Method and device for extracting webpage content
A webpage content and extraction method technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as inclusions, missing content and noise in the extracted content, reduce complexity, overcome uncertainty, and improve accuracy Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
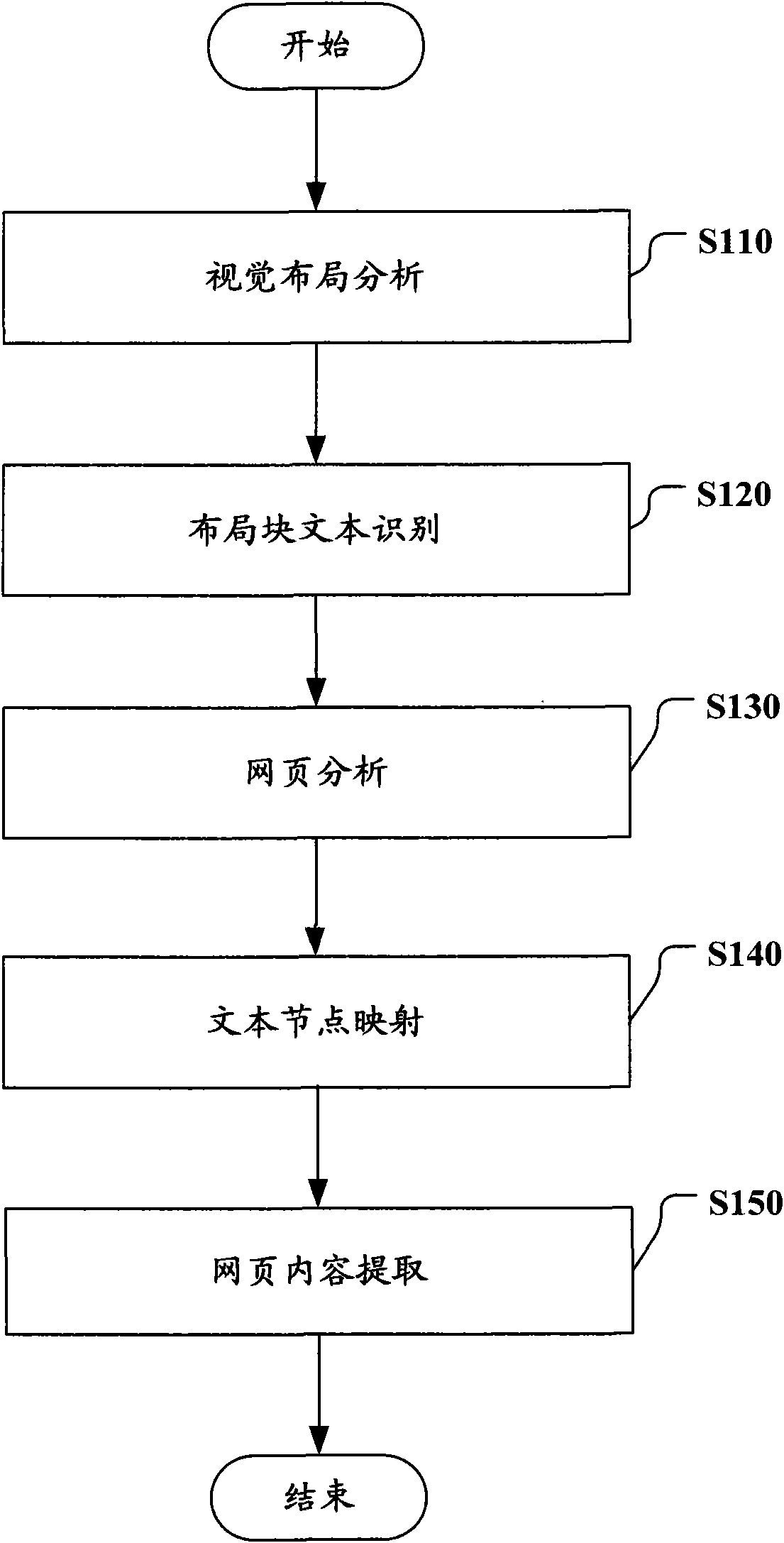
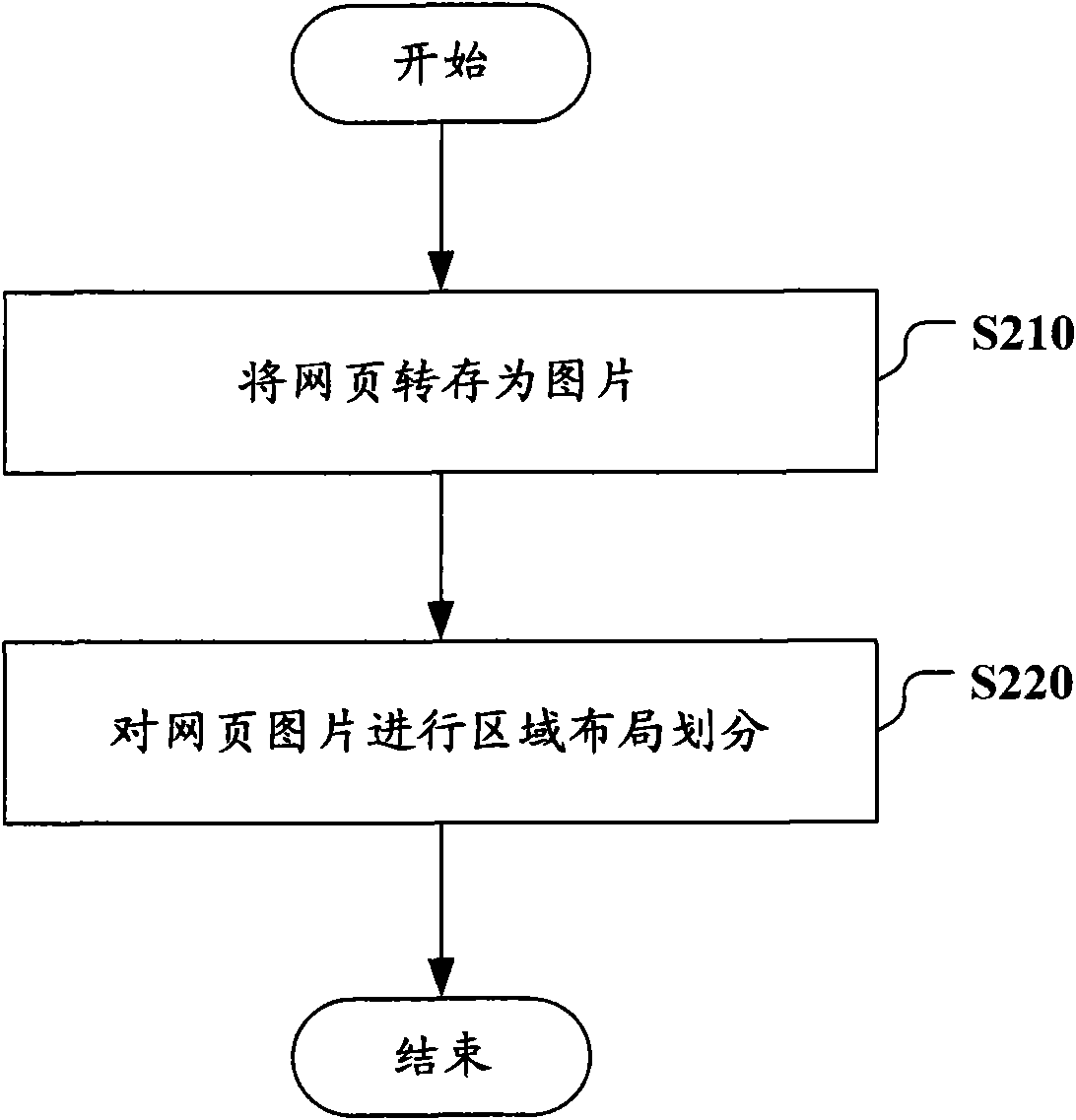
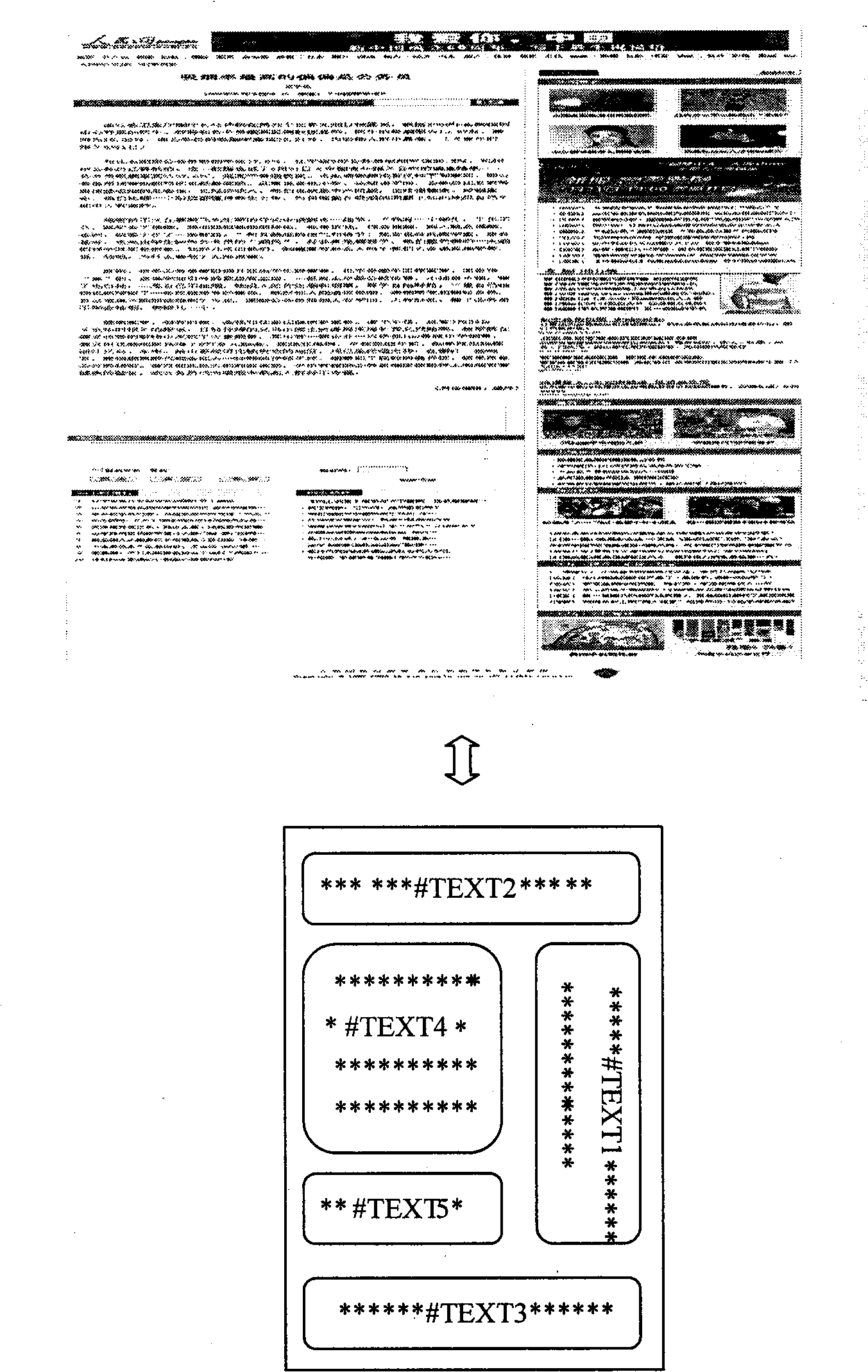
[0023] Hereinafter, exemplary embodiments of the present invention will be described with reference to the accompanying drawings. For the sake of clarity and conciseness, not all features of the actual implementation are described in the specification. However, it should be understood that many implementation-specific decisions must be made during the development of any such actual implementation in order to achieve the developer’s specific goals, for example, compliance with system and business-related constraints, and these The restriction conditions may vary depending on the implementation. In addition, it should also be understood that although the development work may be very complicated and time-consuming, for those skilled in the art who benefit from the present disclosure, such development work is only a routine task.
[0024] Here, it should be noted that, in order to avoid obscuring the present invention due to unnecessary details, only the device structure and / or proc...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More