

Method for separating single-channel mixed voice based on compressed sensing and K-SVD
A K-SVD algorithm and mixed voice technology, applied in voice analysis, instruments, etc., can solve problems such as high algorithm complexity, large differences, and poor practicability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
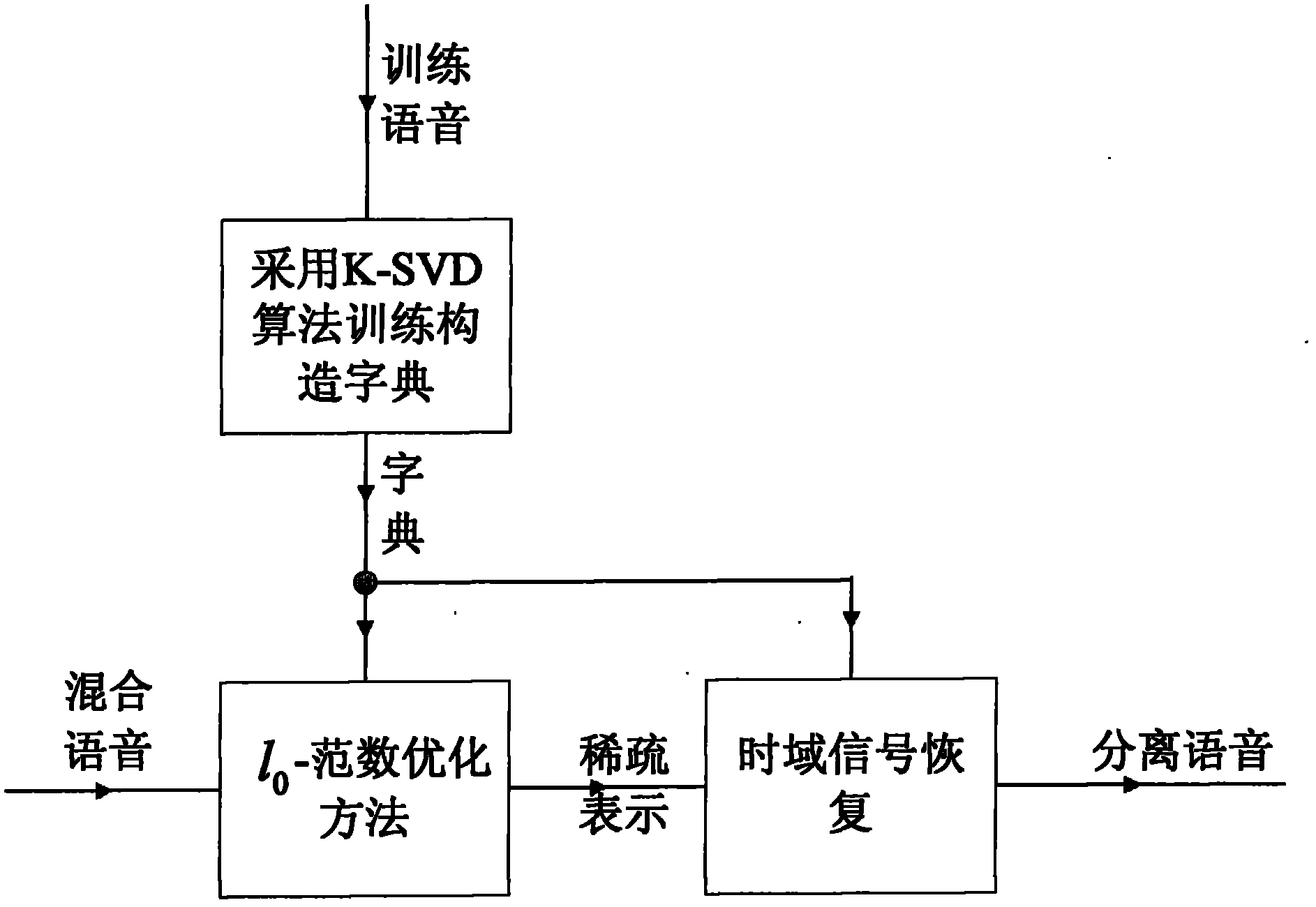
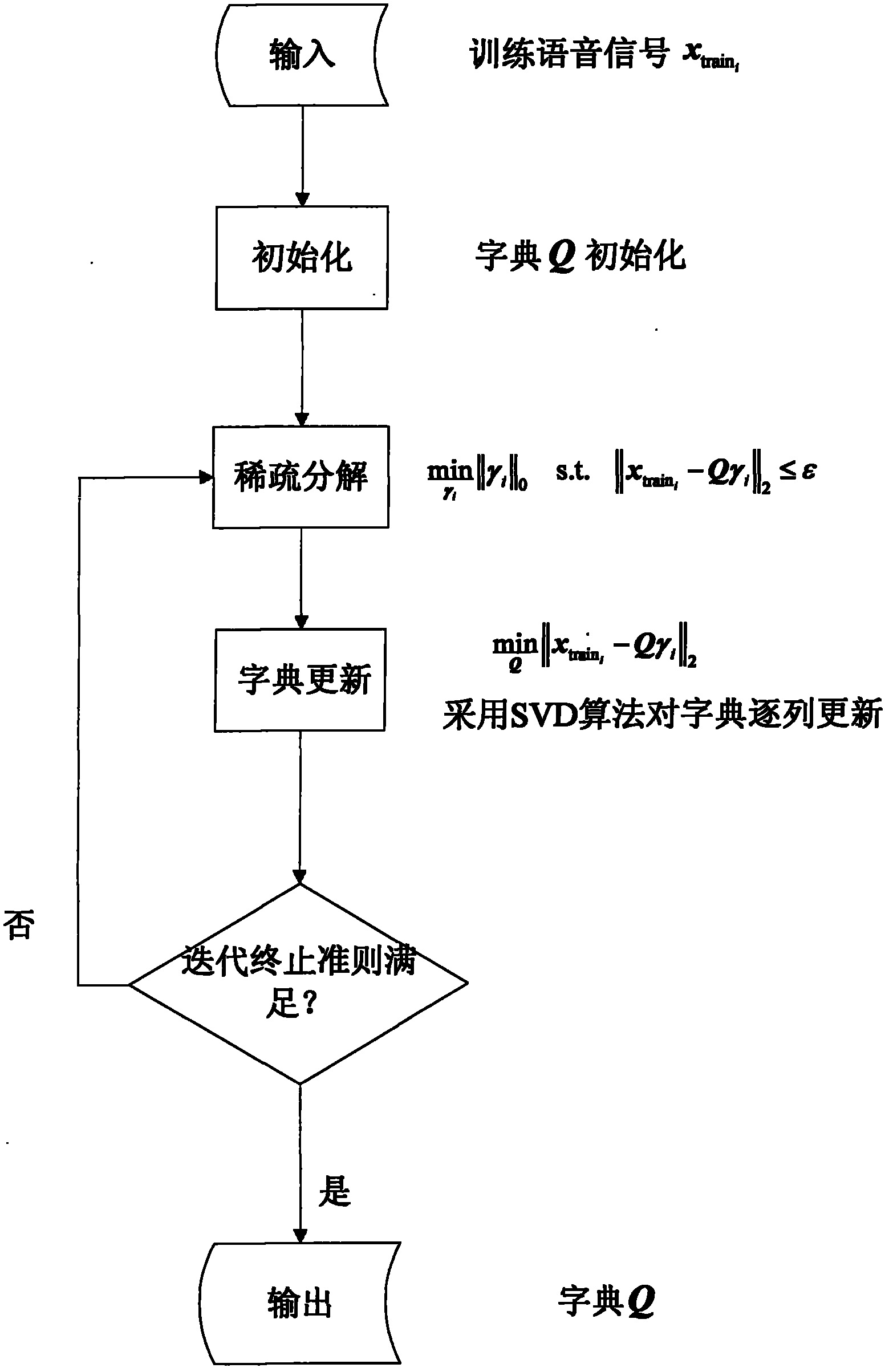
[0048] figure 1 In order to realize the system block diagram of this scheme. As shown in the figure: the present invention first adopts the K-SVD algorithm, trains and constructs a complete dictionary, and then based on the constructed K-SVD dictionary, adopts the method based on l in compressed sensing 0 - Norm-optimized signal reconstruction algorithm for separation of single-channel mixed speech.
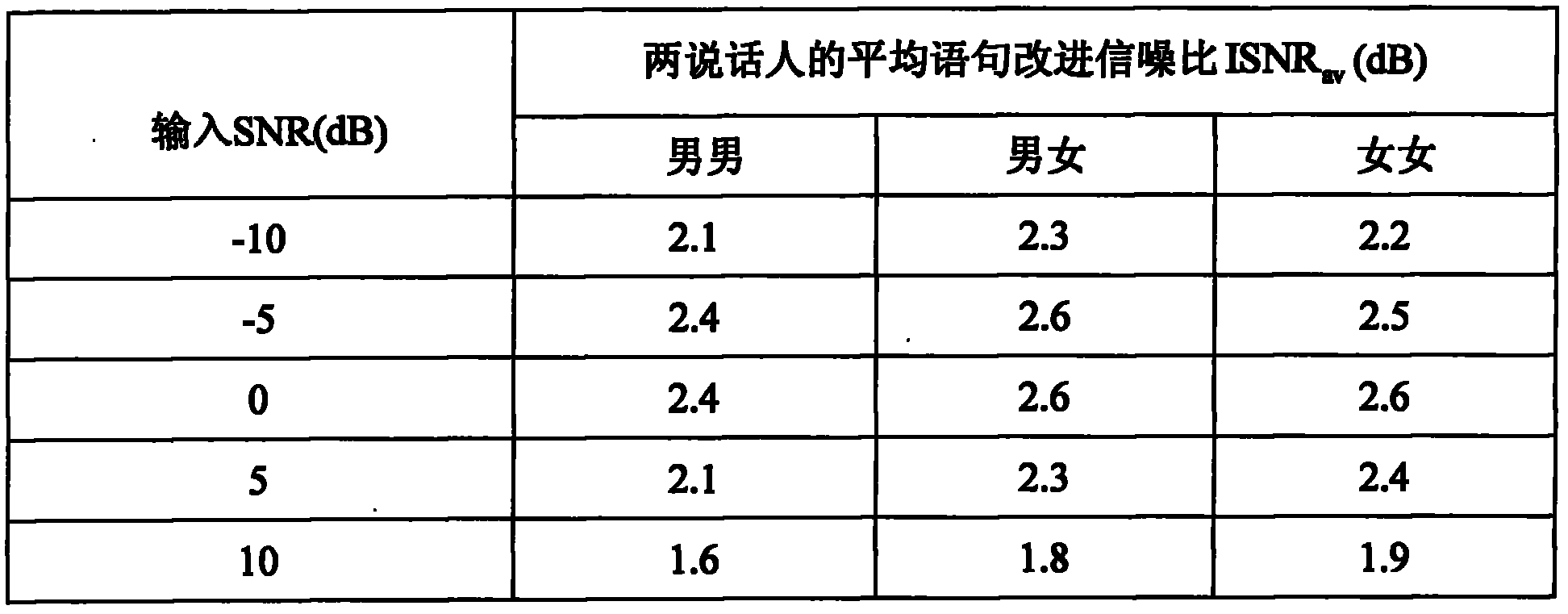
[0049] The speech used in the experiment is a speech with a sampling rate of 16KHZ. There are four speakers, two men and two women. Each speaker takes 40 sentences of Chinese phrase structure to construct training speech. Each speaker randomly selects 5 sentences of Chinese phrase structure as the test speech, and the test speech is different from the training speech. Single channel mixed speech x by two sources Test speech s 1 ,s 2 Overlay acquisition, that is, x=s 1 +s 2 , a total of 100 mixed voices of men and women, 25 mixed voices of men and women, and 25 mixed voice...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More