

Single instruction multiple data (SIMD) vector processor supporting fast Fourier transform (FFT) acceleration
A vector processor and vector operation technology, applied in electrical digital data processing, instruments, memory systems, etc., can solve problems such as on-chip resource occupation, avoid hardware overhead, and ensure performance.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

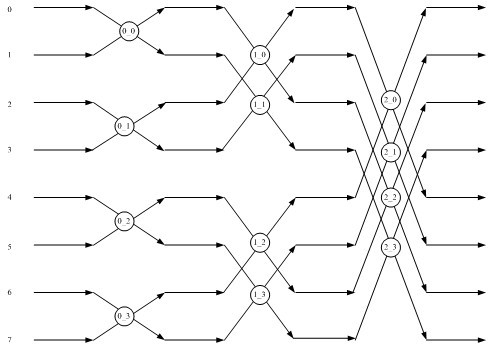
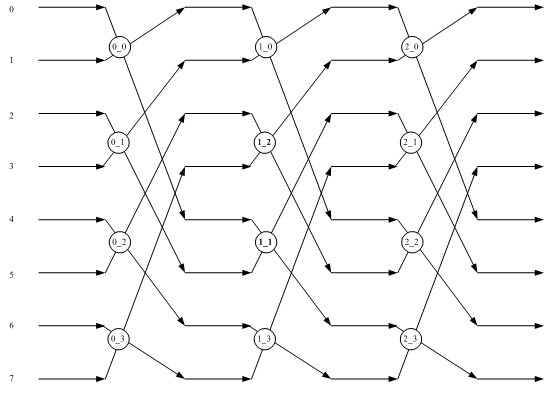
Examples
Embodiment Construction
[0017] The SIMD vector processor supporting FFT acceleration of the present invention will be described in detail below with reference to the accompanying drawings.
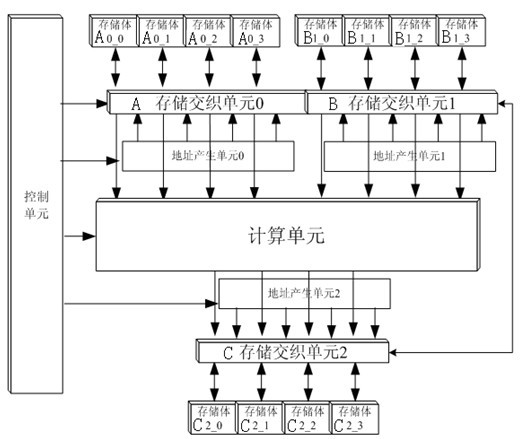
[0018] A SIMD vector processor that supports FFT acceleration, see figure 1 The processor includes a control unit, a calculation unit, a memory subsystem, a storage interleaving unit and an address generation unit.
[0019] The calculation unit supports fast processing of various vector operations. The calculation unit includes 2 complex multipliers and 4 complex adders. It supports 2 data parallel complex multiplication and convolution operations, and 4 data parallel complex addition and subtraction, accumulation Operation, 4 data parallel complex modulus operations, 4 data parallel FFT / IFFT operations, and 8 data parallel real number multiplication, convolution, addition and subtraction, accumulation operations. For the aforementioned n-way data parallel vector operation, n vector units are processed on average per ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More