

Data structure based on cloud computing database system
A data structure and database technology, which is applied in the field of data structure based on cloud computing database system, can solve the problems of unreasonable data structure design, low storage and retrieval efficiency, etc., and achieve the effect of improving retrieval efficiency and saving storage space
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

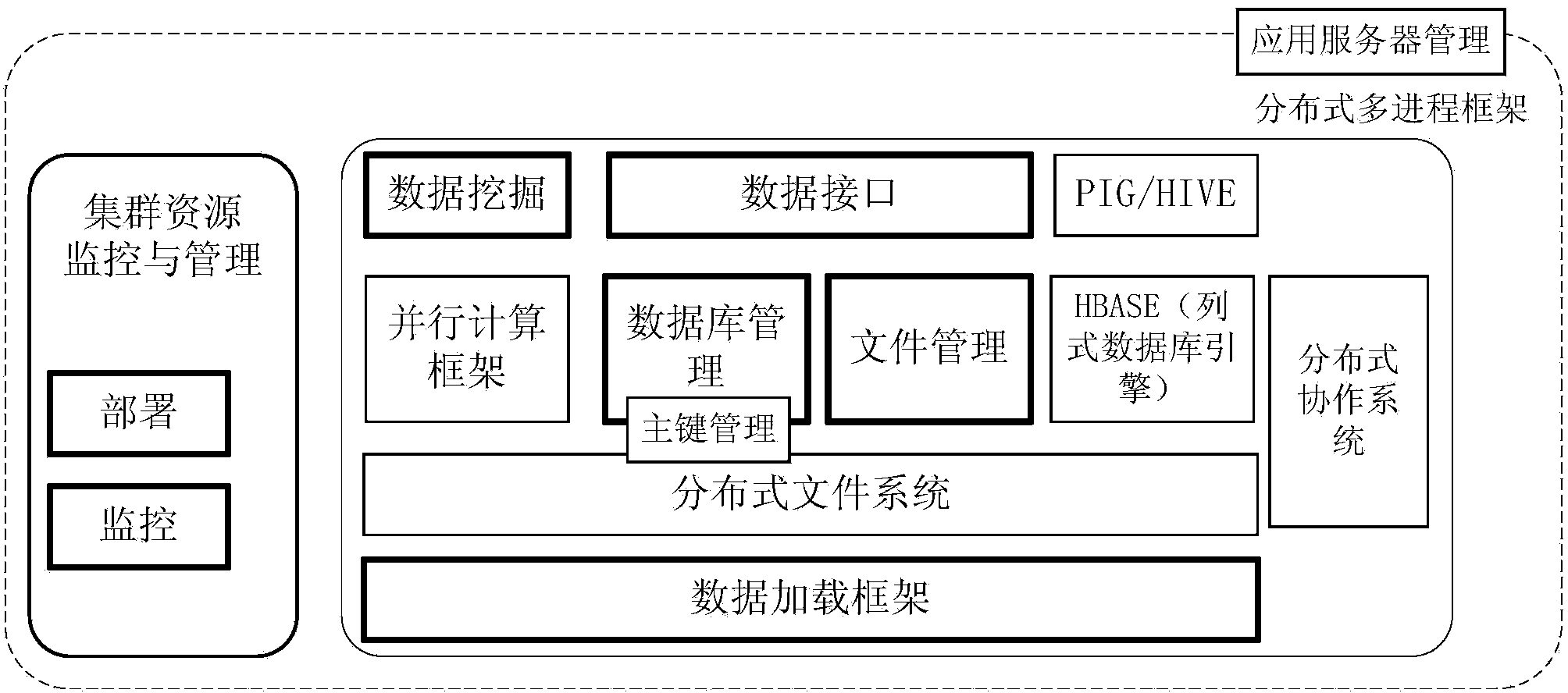
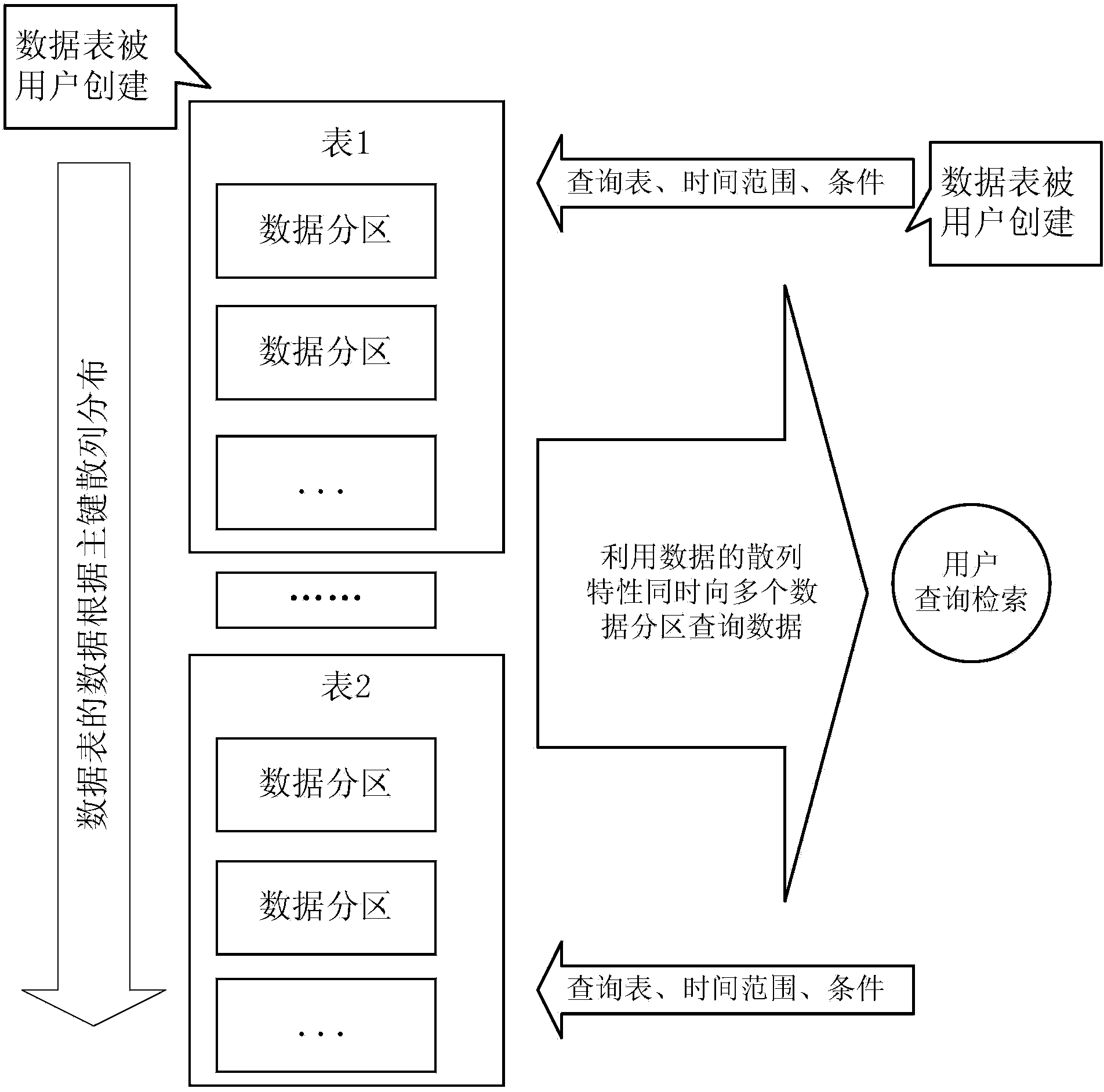
Examples
Embodiment 1
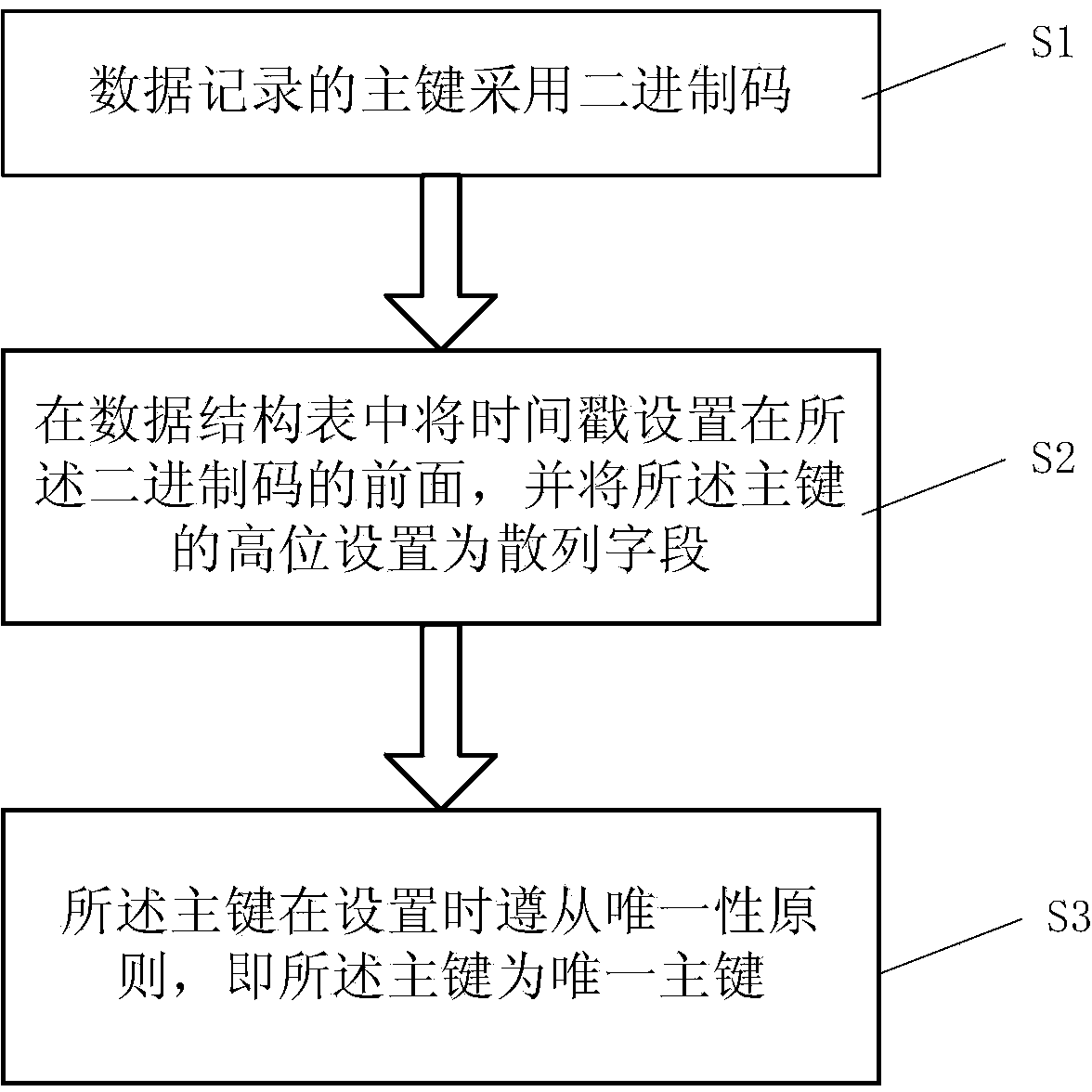
[0030] Embodiment 1: Primary key data structure design for transactional data
[0031] The primary key is a transaction data primary key, and the transaction data has a time attribute, that is, the transaction data primary key has a time attribute. Storing time information in the primary key helps to prompt query retrieval speed.
[0032] Such as Figure 4 As shown, the design steps of the primary key of the transaction data are: Step 11: the transaction data establishes a transaction data table 401 by day; Step 12: the transaction data table 401 includes 6 bytes, and the first 4 bytes are used for storing , hour and millisecond, the last 2 bytes are used for cyclic self-increment by minute; Step 13: the first 4 bytes are set as a hash field, and the last 2 bytes are set as a sequence field. The benefits of this design are many. After the date table, the time information can remove the date part and only keep hours, minutes, and milliseconds, so that 4 bytes can be completed...
Embodiment 2
[0033] Embodiment 2: Primary key data structure design for statistical data
[0034] The primary key is a statistical data primary key, and the statistical data primary key has a time attribute. Statistical data also has a time attribute, and the smallest unit of statistical data is only minutes (pre-statistics in seconds are meaningless).
[0035] Such as Figure 5As shown, the design steps of the statistical data primary key are: Step 21: Statistical data establishes a statistical data table 501 by day; Step 22: The statistical data table 501 includes 6 bytes, and the first byte is used to save minutes information, the second byte is used to save the hour information, and the last four bytes are used to increment by minute; Step 23: the first byte and the second byte are hash fields, and the last four bytes Four bytes are the sequence field. For statistical data, we also use daily data sub-tables. After pressing the day table, the time information only needs to keep hour...
Embodiment 3
[0036] Embodiment 3: Aiming at the design of the above data structure model, the present invention designs a factory class for producing primary keys, which needs to be associated with tables to help tables generate unique key values.
[0037] RowkeyFactory (base class)
[0038] RowkeyFactory is divided into three types according to the type of data table. Factory information is stored by instance. There are different storage rules for different types of data tables, and each factory instance.
[0039]
[0040] RowkeyFactory4Trans class design
[0041]
[0042]
[0043] RowkeyFactory4Stat class design
[0044]
[0045]
[0046]
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More