

Non-uniform big data classifying method
A classification method and big data technology, applied in text database clustering/classification, unstructured text data retrieval, electronic digital data processing, etc., can solve problems such as high complexity of big data classification and big data algorithms, and reduce complexity degree, improve grades, and improve the effect of classification grades
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0035] It is given that the simulated big data instance contains two million, and the dimension of each instance is 1000 dimensions. The entire data set is divided into two categories, the first category contains 1.99 million instances, and the second category only contains 10,000 instances. This dataset is randomly generated and belongs to the imbalanced big data binary classification problem.
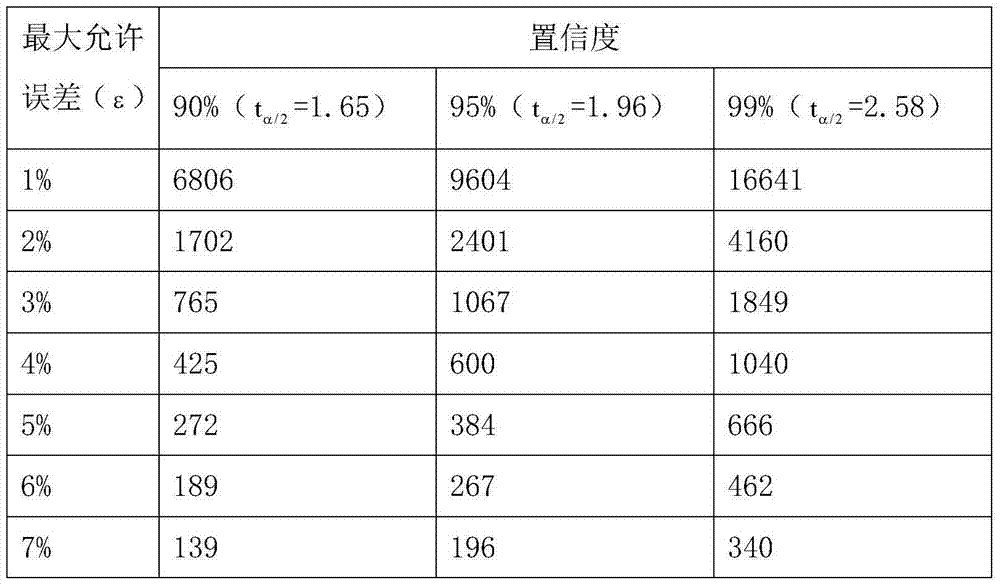
[0036](1) Determine the confidence level of 99% and the maximum allowable error of 1%. So the sample size per dataset per class is 16641. According to the proportion, 10,000 instances are extracted from class A (data set containing 1.99 million instances), plus 10,000 instances of non-class A, each data set contains 20,000 instances. Common PCs can usually easily apply common meta-classifiers to classify datasets containing 20,000 instances.
[0037] (2) According to the above method, a total of 10 sub-datasets are generated in this example. Establish 10 classifiers using the near...
Embodiment 2
[0041] Given a simulated big data instance containing 20 million, the dimension of each instance is 1000 dimensions. The entire data set is divided into three categories, among which category A contains 12 million instances, category B contains 7.9 million instances, and category C contains 100,000 instances. This dataset is randomly generated and belongs to the imbalanced big data multiclass classification problem.
[0042] (1) Determine the confidence level of 95% and the maximum allowable error of 1%. The sample size for each dataset is 9604 per class. It is a bit difficult for a general computer to process 300,000 data. Therefore, three classes need to be sampled.
[0043] (2) Sample 10 data for class A, and each data set contains 20,000 instances (note: the number of instances only needs to exceed 9604). More specifically, 10,000 samples are randomly drawn from class A, then 5,000 samples are randomly drawn from class B, and 5,000 samples are randomly drawn from class...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More