

Text Semantic Representation Method Based on Aggregation Weighted Matrix Compression Algorithm
A compression algorithm and weighted matrix technology, applied in computing, instrumentation, electrical and digital data processing, etc., can solve the problems of ignoring word vector combination, missing document vector information, weight estimation deviation, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

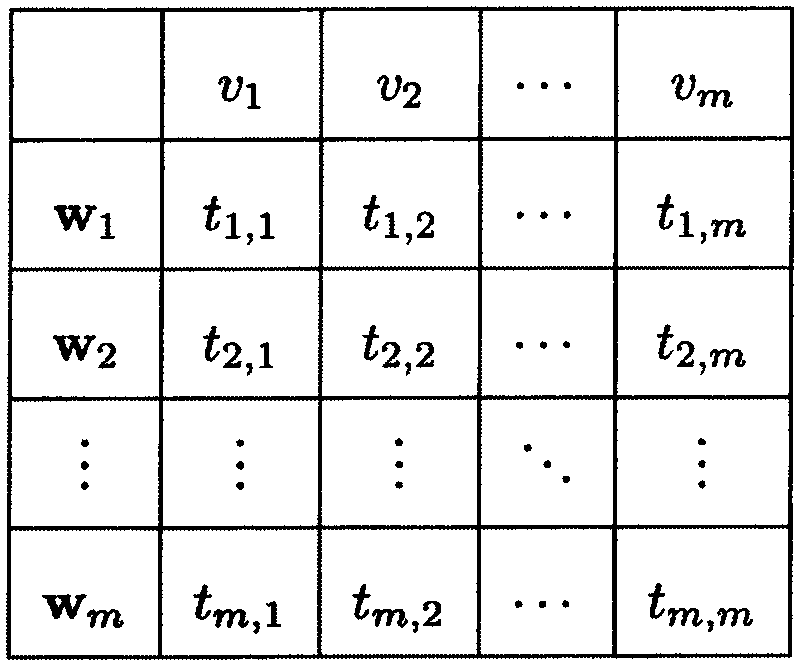
Examples
Embodiment Construction
[0017] 1. Concepts and definitions related to the present invention.
[0018] 1. Glossary
[0019] For a given corpus, the set of all distinct words v in the corpus is called vocabulary V.
[0020] 2. Word frequency in the document
[0021] for any word w i , which in any document d k The frequency of occurrence in is defined as the word frequency in the document, and the statistical method is:
[0022]
[0023] in for w i in document d k The number of occurrences in l k for document d k length.
[0024] 3. Document frequency
[0025] for any word w i , whose document frequency is defined as:
[0026]
[0027] where n is the number of documents in a given corpus; n i For the word w contained in the given corpus i number of documents.
[0028] 4. Inverse document frequency
[0029] The natural logarithm of the reciprocal of the document frequency is generally called the inverse document frequency:
[0030]
[0031] 5. Co-occurrence frequency
[0032] F...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More