

Spark streaming based big data stream processing method and system
A processing method and technology of a processing system, applied in the field of big data flow processing, can solve problems such as incorrect update of variable state, difficulty, non-native support, etc., and achieve better fault tolerance, faster processing speed, and improved processing efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0049] The principles and features of the present invention are described below in conjunction with the accompanying drawings, and the examples given are only used to explain the present invention, and are not intended to limit the scope of the present invention.
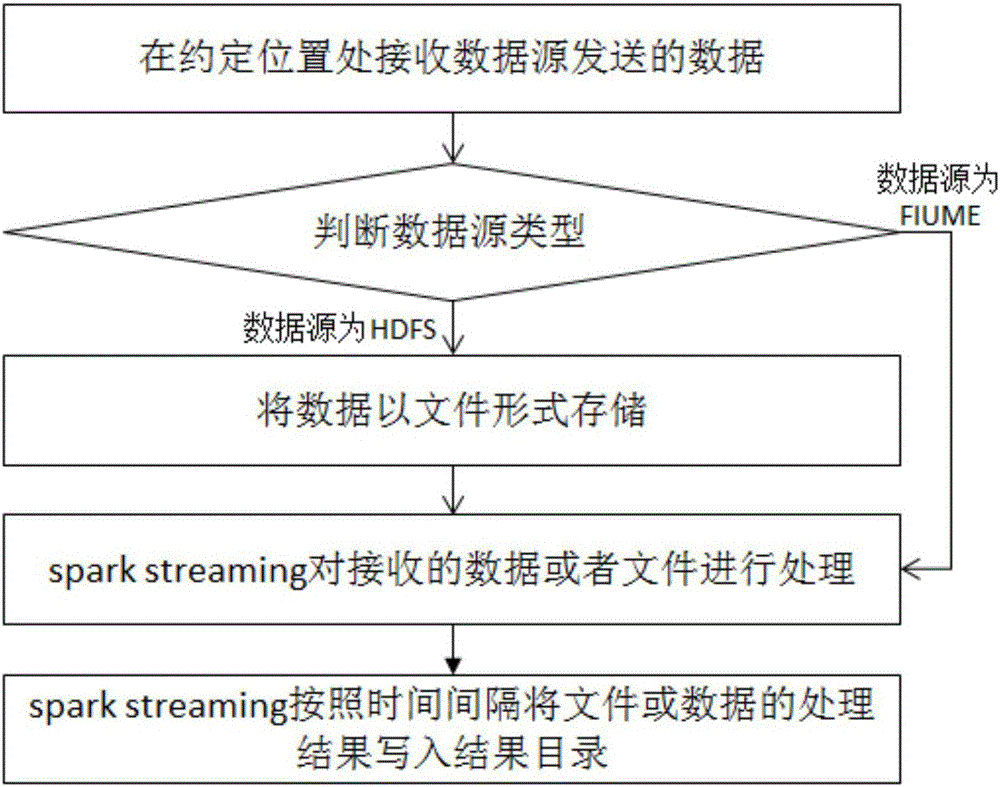
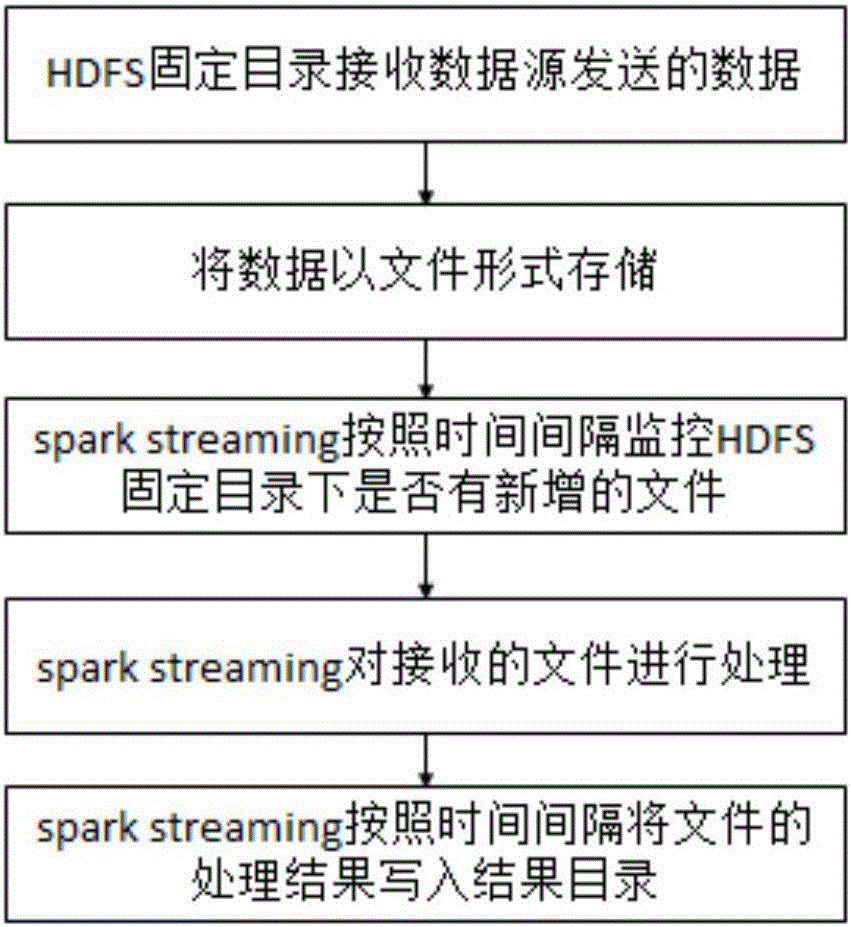
[0050] Spark Streaming is an extension of the spark core API, which enables high-throughput, fault-tolerant stream processing of real-time data streams. There are many data sources for Spark Streaming, including kafka, flume, twitter, ZeroMQ or traditional TCP sockets.
[0051] Spark Streaming is an extension of the core Spark API. It does not process data streams one at a time like Storm, but pre-segments them into batch jobs at time intervals before processing. Spark's abstraction for continuous data flow is called DStream (DiscretizedStream), a DStream is a micro-batching (micro-batching) RDD (elastic distributed data set); and RDD is a distributed data set that can be The two methods operate in parallel, namely...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More