

WiFi indoor locating method based on domain clustering
An indoor positioning and clustering technology, which is applied in the direction of instruments, measuring devices, and re-radiation, can solve the problems of position estimation accuracy, AP selection algorithm performance, and the fuzzy definition of the optimal AP subset number. The effect of precision and reliability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0019] In order to facilitate those of ordinary skill in the art to understand and implement the present invention, the present invention will be described in further detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the implementation examples described here are only used to illustrate and explain the present invention, and are not intended to limit this invention.
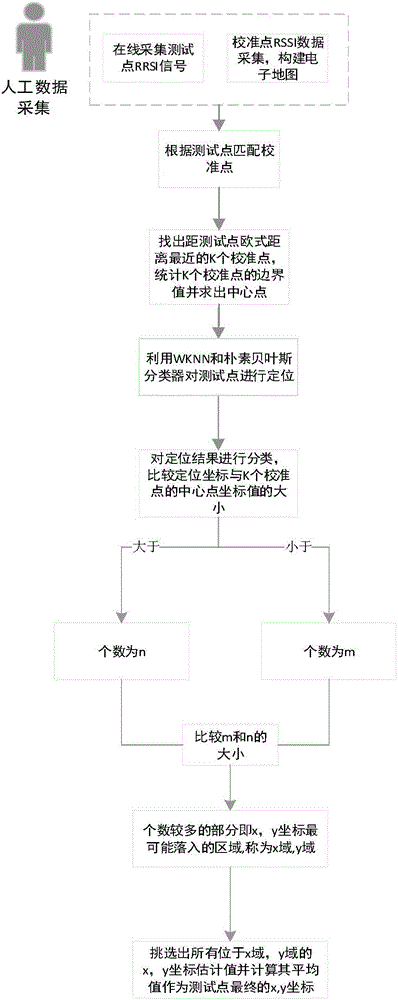
[0020] please see figure 1 , a kind of WiFi indoor positioning method based on domain clustering provided by the present invention, comprises the following steps:
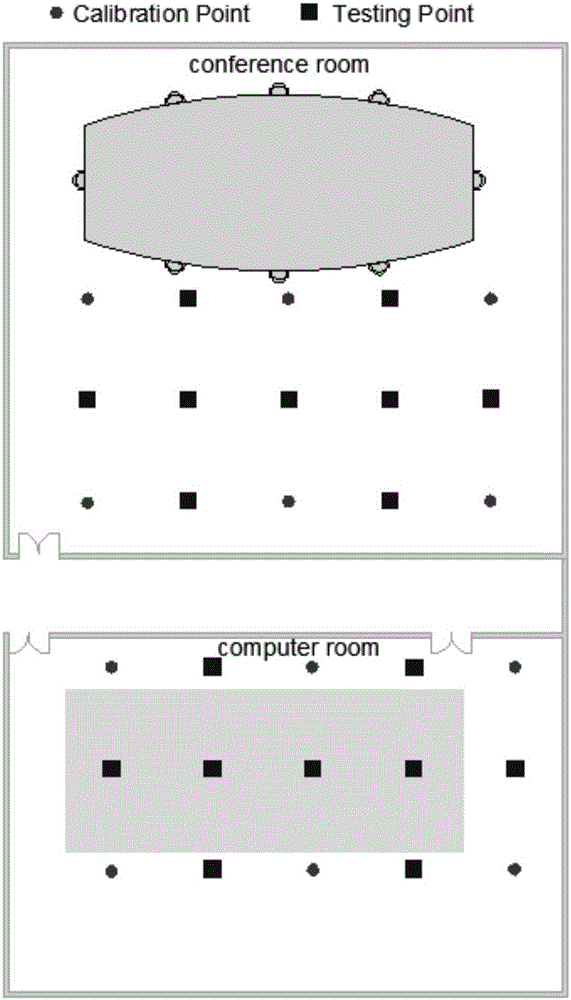
[0021] Step 1: Select 6 calibration points in two different indoor environments (see figure 2 ), collect the WiFi signal strength information at the calibration point, and the duration is 2min; associate the signal strength information with the location information of the calibration point to form a location fingerprint, and obtain the location fingerprint library;
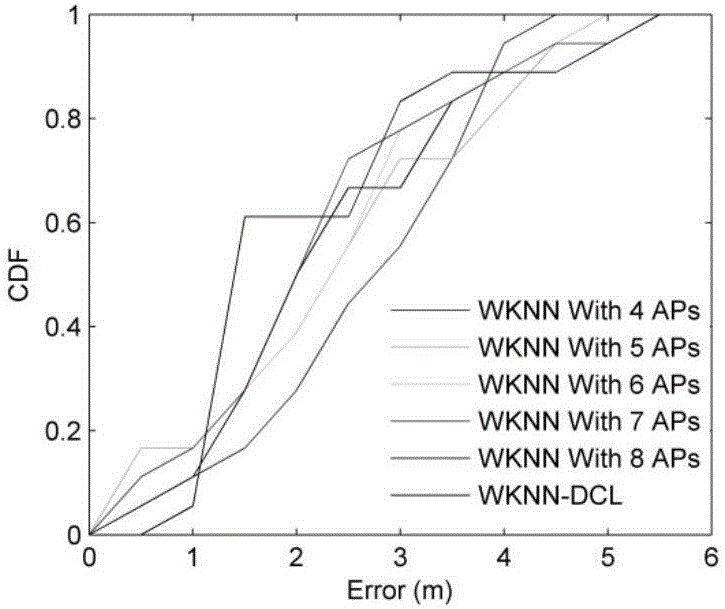
[0022] Step 2: Collect WiFi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More