

Voice recognition result error correction method
A technology of speech recognition and error correction method, which is applied in speech recognition, speech analysis, natural language data processing, etc., and can solve problems that affect the promotion of speech recognition technology, lack of recognition error correction means, and high error rate of speech recognition.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
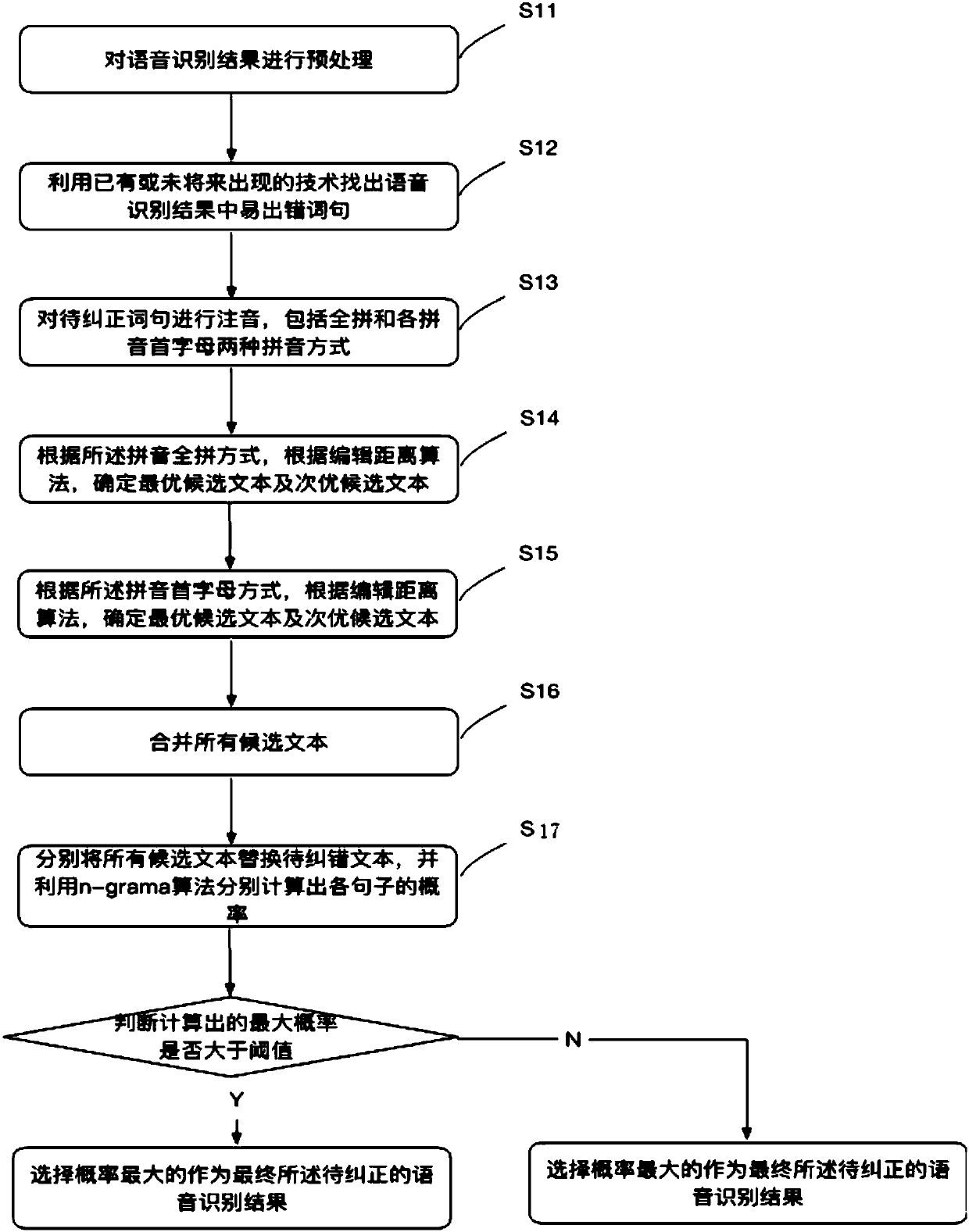
[0017] see figure 1 , the method of the present embodiment comprises:
[0018] S11: Perform text operations such as word segmentation, part-of-speech tagging, stop word removal, and grammatical analysis on the speech recognition results
[0019] S12: According to existing or future technologies, find out words and characters to be corrected that are error-prone or important to text semantic analysis. Pay special attention to verb-object structure phrases, verbs, nouns and words that do not appear in the dictionary database in the speech recognition results.
[0020] S13: Carry out phonetic notation on the word or character to be corrected, and obtain the corresponding pinyin of the speech recognition result to be corrected, and the corresponding pinyin refers to no tone.
[0021] This situation can be divided into several situations, which are explained in detail as follows:
[0022] Homonyms, take full spelling:
[0023] For example, the speech recognition result to be co...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More