

Implementing method for multidimensional index structure OBF-Index in Hadoop environment
A technology of obf-index and index structure, applied in the field of cloud storage, which can solve problems such as high false positive rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

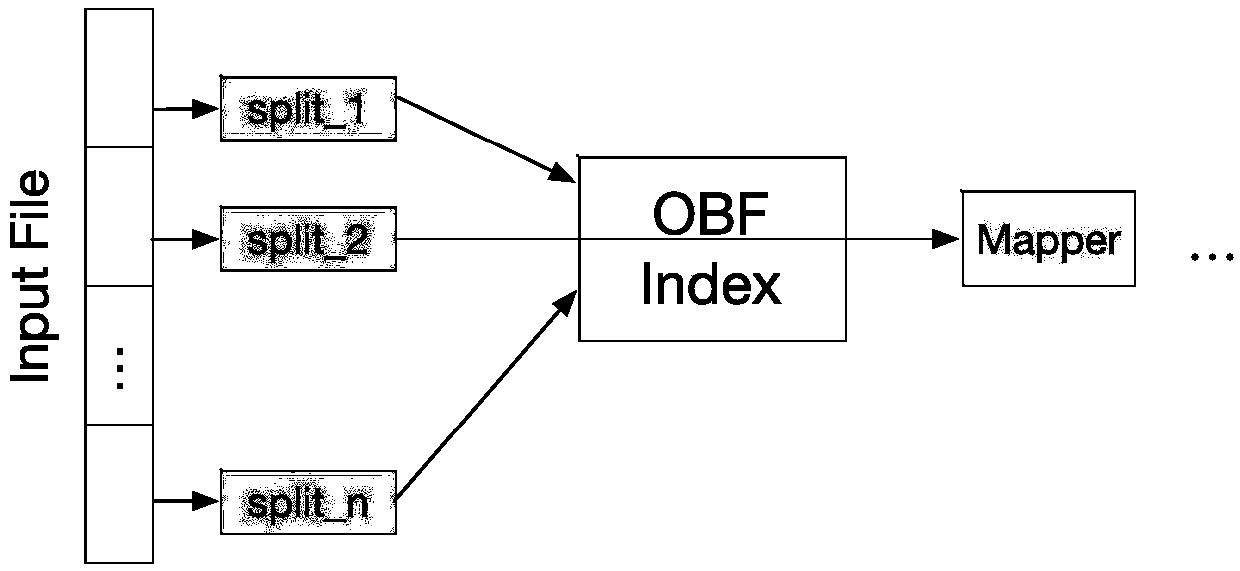
Examples
Embodiment
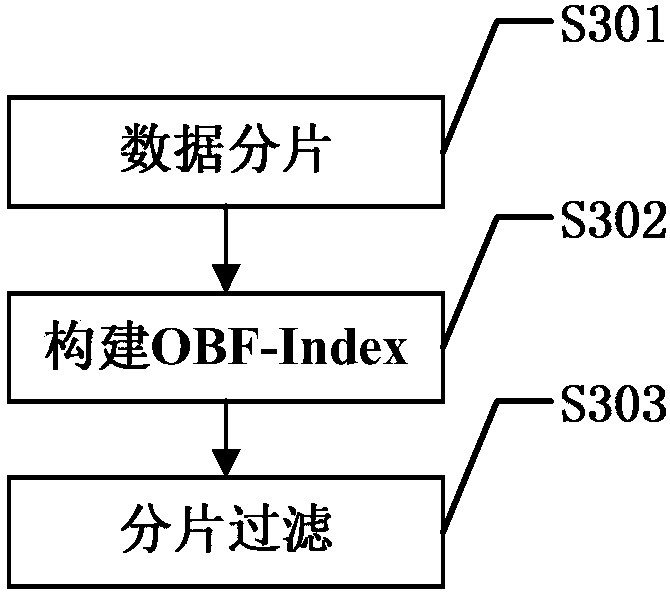
[0029] In order to better illustrate the technical solution of the present invention, firstly, the idea of the present invention is briefly described.
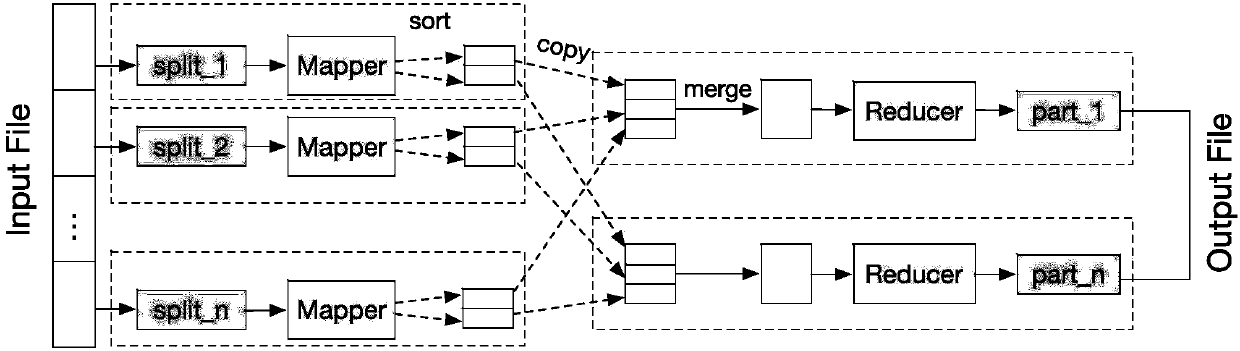
[0030] In Hadoop, the purpose of quickly processing data is achieved through the parallel operation of multiple Mappers and multiple Reducers. Because the data stored on HDFS is generally in the order of GB, TB or more, it is impossible to allocate all the data to one machine for execution when executing a task. Therefore, before executing Map, Hadoop first divides the input data into fixed-size blocks to obtain data fragments (InputSplits), and then each fragment will be assigned to an independent Mapper.
[0031] figure 1 It is a schematic diagram of the original MapReduce process. Such as figure 1As shown, in the original MapReduce process, the Mapper receives data fragments, and the Reducer often copies and processes data from the relevant Mapper at runtime, so the resources of the Reducer node are less than that of t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More