

A preprocessing method of multi-source heterogeneous big data
A multi-source heterogeneous and heterogeneous data source technology, applied in the field of big data processing, can solve the problems of insufficient research on semi-structured and unstructured data preprocessing, and can not meet user needs well, so as to reduce storage capacity. Resources and network bandwidth, strong practicability, and the effect of improving data storage efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0035] The present invention will be further described below in conjunction with specific examples.
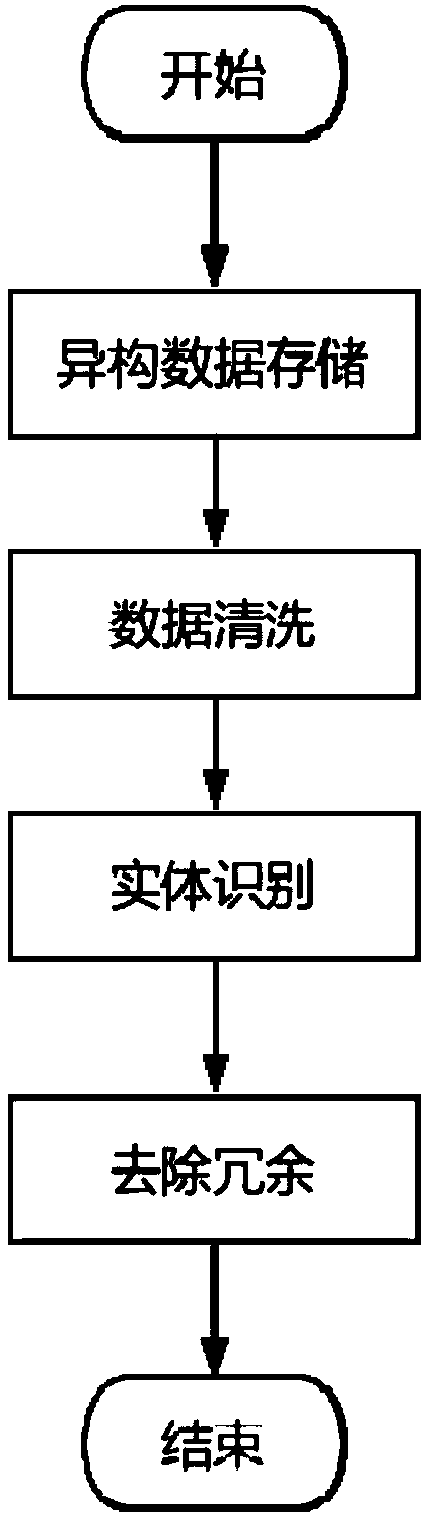
[0036] Such as figure 1 As shown, the preprocessing method for multi-source heterogeneous big data provided in this embodiment includes the following steps:
[0037] Step 1: Storage of heterogeneous data. Extract data from multiple heterogeneous data sources and upload them to the distributed file system HDFS for storage. The invention provides support for multiple data source formats, including: Txt, Csv, Xsl, database data, jpg, mp4, etc., and provides interface standards to expand new data sources.
[0038] For text files, such as Txt and Csv, by designing a text storage function, the text data is read from the text file and stored in the distributed file system HDFS.
[0039] For the Xsl file, by designing the Xsl storage function, the excel data is read from the Excel file and stored in the distributed file system HDFS.
[0040] For database data, such as MySQL, Oracl...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More