

Method for establishing model for obtaining glomerular filtration rate and application
A technology of glomerular filtration rate and establishment method, which can be applied in medical simulation, health index calculation, medical informatics and other directions, and can solve the problem of inaccurate estimation of glomerular filtration rate.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

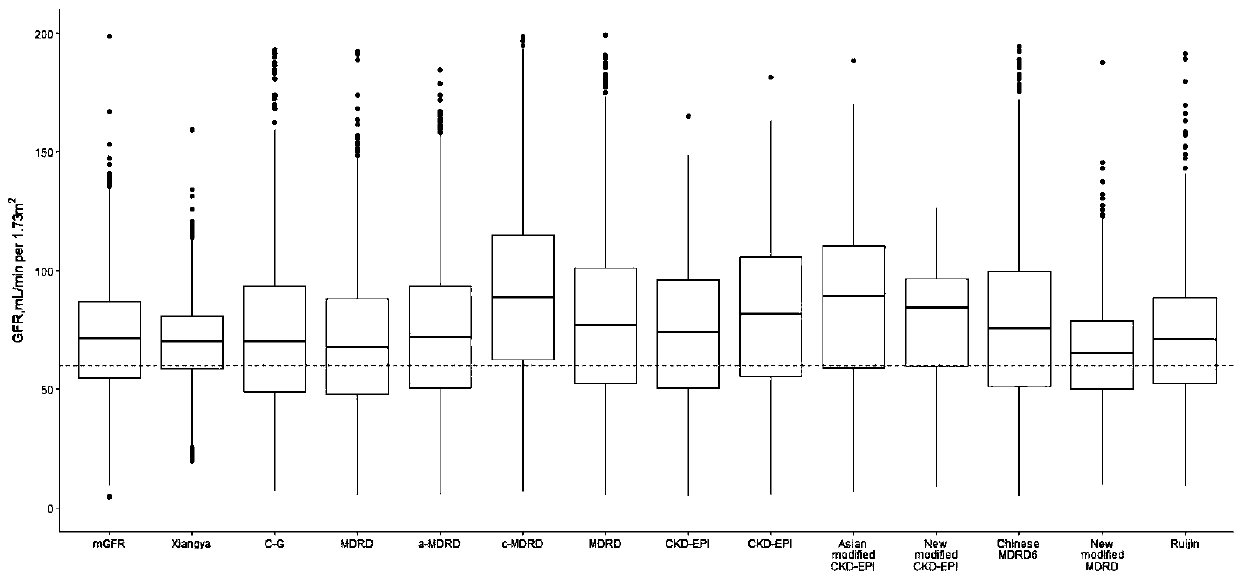
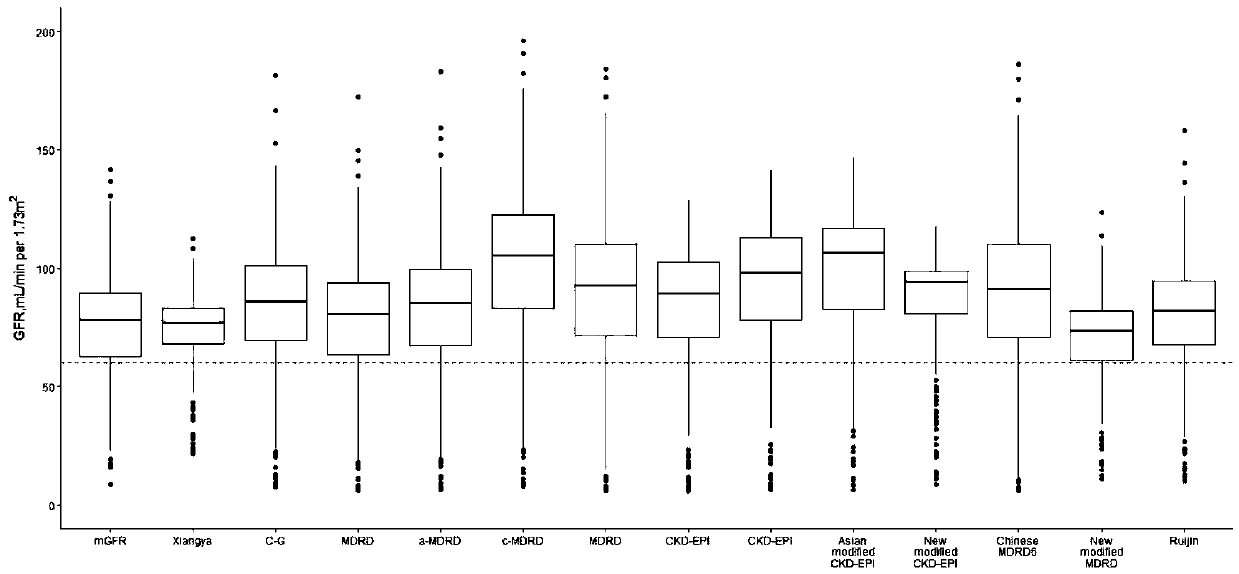
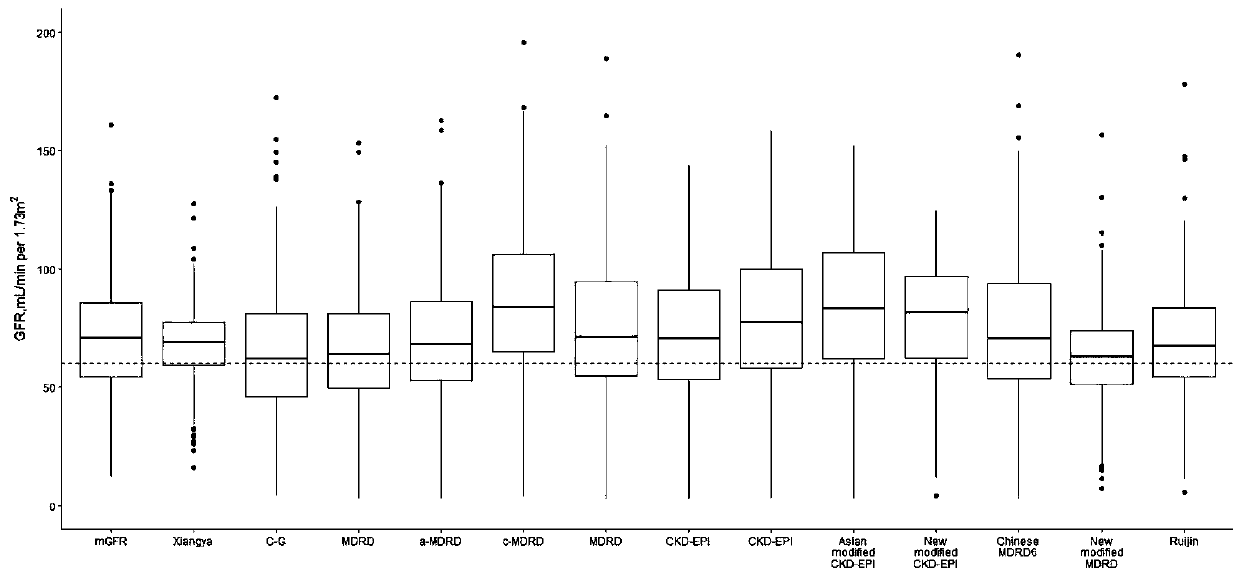
Examples
Embodiment Construction
[0027] In order to make the above objects, features and advantages of the present invention more comprehensible, specific implementations of the present invention will be described in detail below in conjunction with the accompanying drawings. In the following description, numerous specific details are set forth in order to provide a thorough understanding of the present invention. However, the present invention can be implemented in many other ways different from those described here, and those skilled in the art can make similar improvements without departing from the connotation of the present invention, so the present invention is not limited by the specific implementations disclosed below.
[0028] The patient data collected in this specific embodiment comes from the Third Xiangya Hospital (TXH) and the Second Xiangya Hospital (SXH) of Central South University (Changsha, Hunan Province) in central China (Changsha City, Hunan Province), and the First Affiliated Hospital (FX...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More