

Unbalanced data classification method based on mixed sampling and machine learning
A machine learning and mixed sampling technology, applied in the direction of instruments, computer components, character and pattern recognition, etc., can solve the problem of not being able to achieve complete information acquisition or proper fitting, deviation from the true distribution of minority classes, and over-generalization and other problems, to reduce the possibility of over-fitting and over-generalization, improve the degree of attention, and achieve the effect of high classification accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

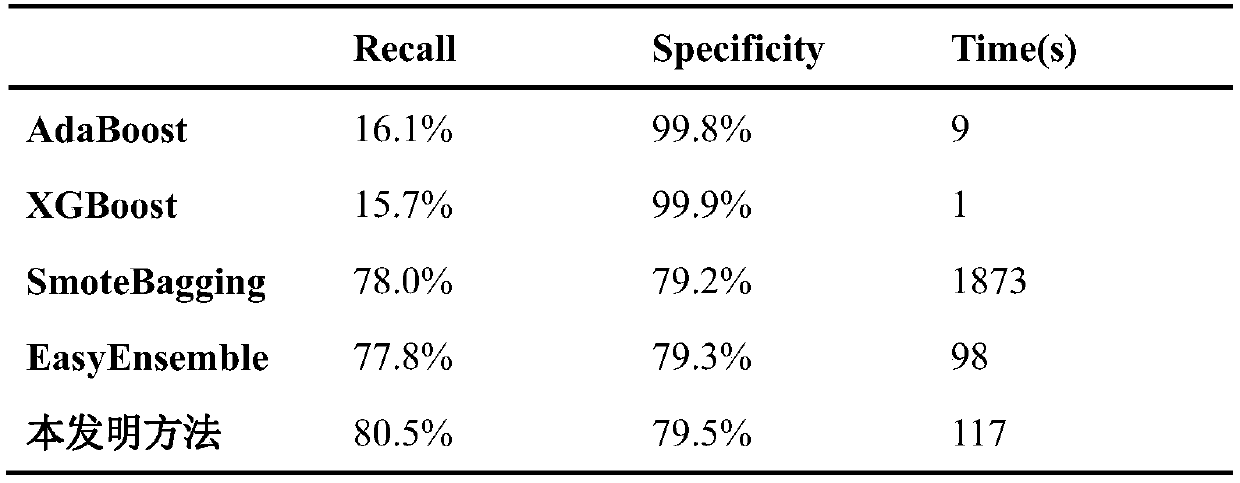
Examples
Embodiment Construction
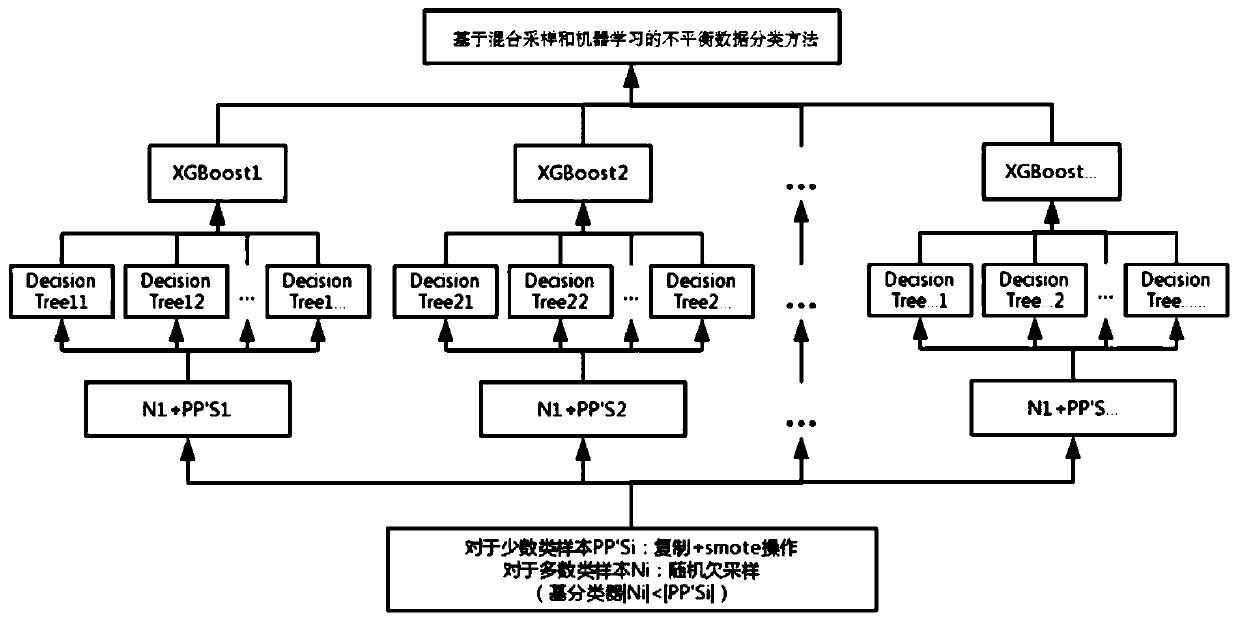
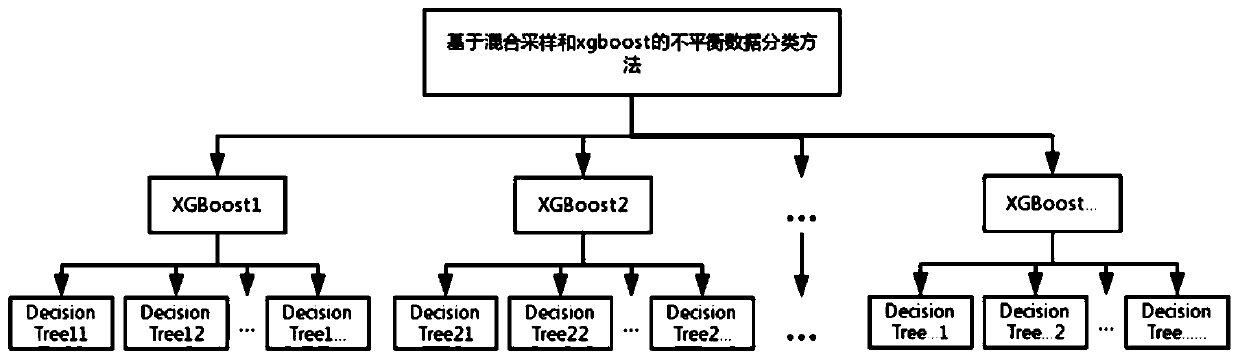
[0029] Such as figure 1 and figure 2 As shown, the imbalanced data classification method based on hybrid sampling and machine learning includes the following steps:
[0030] Step 1: extract several majority class samples from the majority class sample set in the original learning sample set, extract several minority class samples from the minority class sample set in the original learning sample set, and use the extracted majority class samples and minority class samples to synthesize the training set; The complement set of the training set in the original learning sample set is defined as the test set; among them, the ratio of the number of minority class samples to the number of majority class samples in the training set is p, and the ratio of the number of minority class samples to the number of majority class samples in the test set is q, p =q.
[0031] Step 2, for the minority class sample set P in the training set, copy P to generate a sample set P', use P and P' to s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More