

Image-text cross-modal retrieval method, system and device and storage medium
A cross-modal, graphic-text technology, applied in still image data retrieval, unstructured text data retrieval, digital data information retrieval, etc. achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
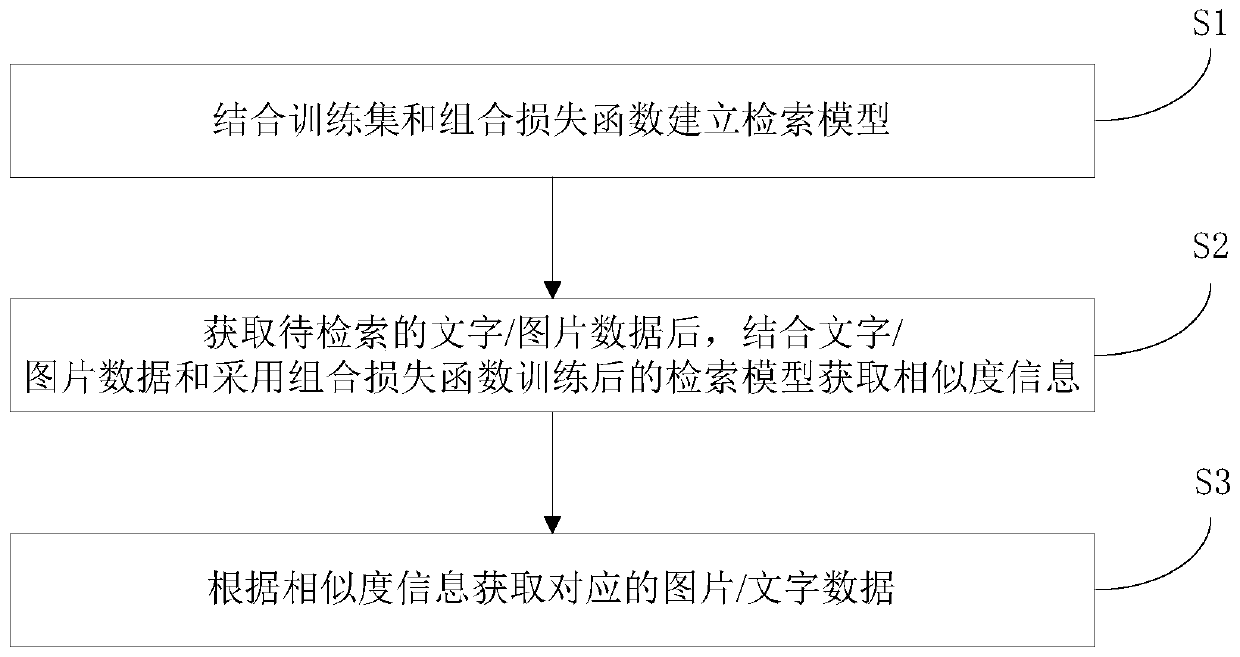
[0056] Such as figure 1 As shown, this embodiment provides a cross-modal image-text retrieval method, including the following steps:
[0057] S1. Combining the training set and the combined loss function to establish a retrieval model.
[0058] S2. After obtaining the text / picture data to be retrieved, combine the text / picture data with the retrieval model trained using the combined loss function to obtain similarity information.
[0059] S3. Obtain corresponding image / text data according to the similarity information.
[0060] The training set includes a text training set and a picture training set. The training set is input into the deep neural network framework for training to obtain a model, and then the model is classified and trained through a combined loss function to capture the potential information between the picture and the text, and finally Generate a retrieval model. When it is necessary to retrieve pictures based on text, input the text into the retrieval mod...
specific Embodiment
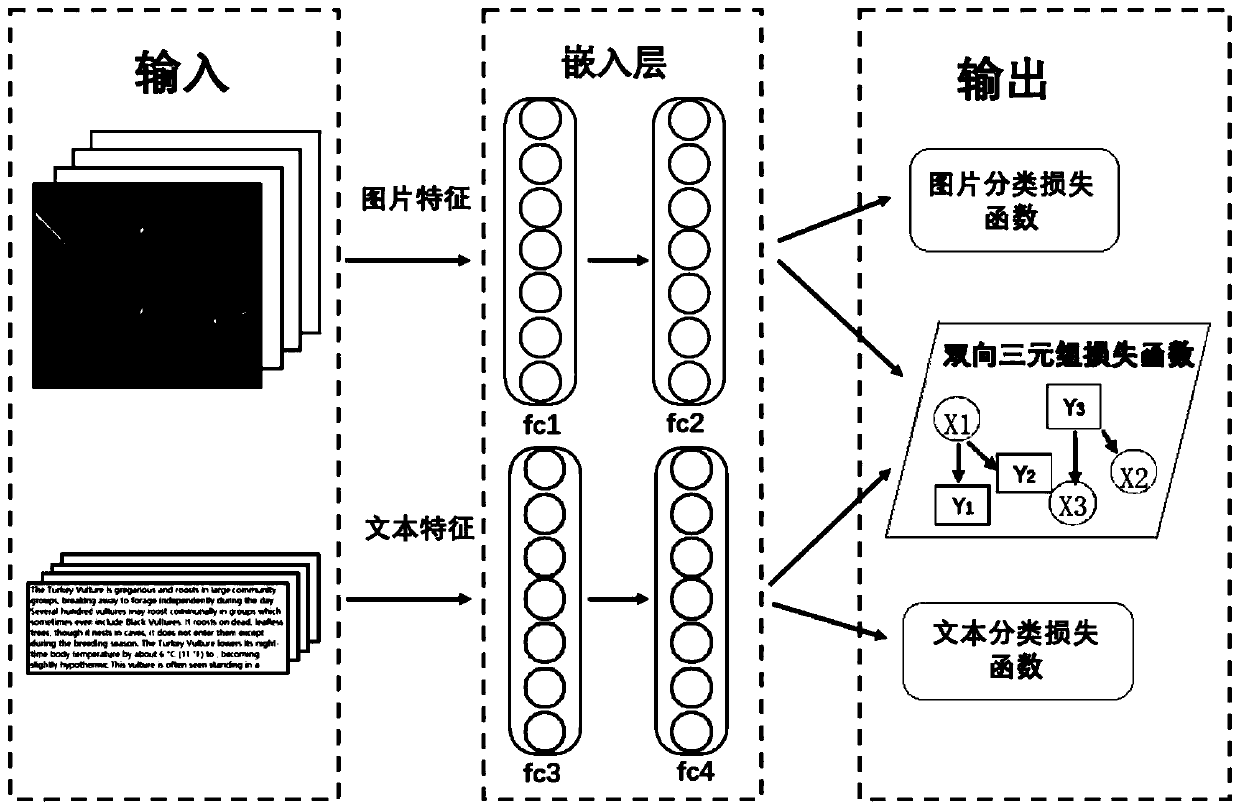
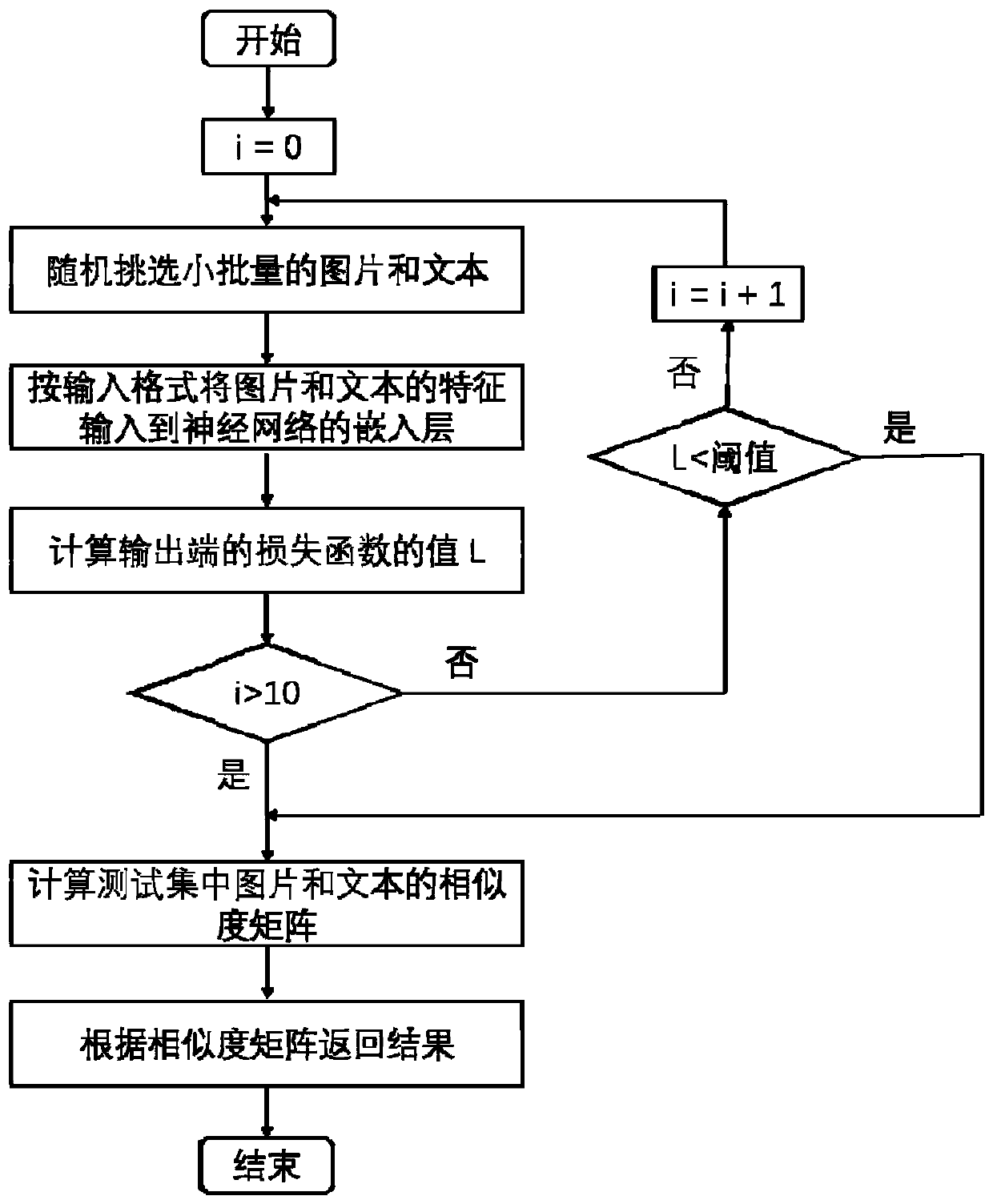
[0089] Below, combine figure 2 and image 3 Explain in detail the steps of building a detection model.
[0090] First, assume that the set of pictures is represented by I={x 1 , x 2 ,...,x n ,} means that the text set is represented by T={y 1 ,y 2 ,...,y n ,}express. The paired picture text collection uses R={P 1 , P 2 ,...,P n ,} means that each pair of picture and text P i =(z i ,y i ) contains x i d of the picture I Dimensional image features and y i text d T Dimensional text features. Then use the Euclidean distance to define the similarity between the picture and the text, the formula is as follows:
[0091]
[0092] where f I (.) is the embedding layer function of the picture of the Euclidean distance, f T (.) is the text embedding layer function. D(.,.) is the distance metric in Euclidean space. D(f I (x i ), f T (y i )) The smaller the distance, it means that the picture x i and the text y i more similar. We employ a pair ranking model ...
Embodiment 2
[0121] Such as Figure 4 As shown, this embodiment provides a graphic-text cross-modal retrieval system, including:
[0122] The calculation module is used to obtain the similarity information by combining the text / picture data and the retrieval model trained by the combined loss function after obtaining the text / picture data to be retrieved;
[0123] The obtaining module is used to obtain corresponding picture / text data according to the similarity information.
[0124] A graphic-text cross-modal retrieval system in this embodiment can execute a graphic-text cross-modal retrieval method provided in Embodiment 1 of the method of the present invention, can execute any combination of implementation steps in the method embodiments, and has corresponding functions and beneficial effects.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More