

Video frame synthesis method based on tensor
A synthesis method and video frame technology, applied in the field of computer vision, can solve the problems of complex network structure, affecting the effect of model training, etc., and achieve the effect of good synthesis effect, high recovery or prediction accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0025] During the actual transmission of video, due to the influence of transmission conditions or other interference factors, frame loss often occurs. Finding effective video frame synthesis methods to restore lost frames can improve the quality of video. The video frame prediction can predict future frames through existing frames, predict the future state of the target, and learn the future actions of people or an object in the video. The synthesis of video frames has attracted more and more attention, but the existing neural network-based methods require a large amount of training data, and the existing tensor methods cannot obtain enough information due to the lack of the entire frame, and the recovery accuracy is low, so they cannot Effectively used for video frame compositing.
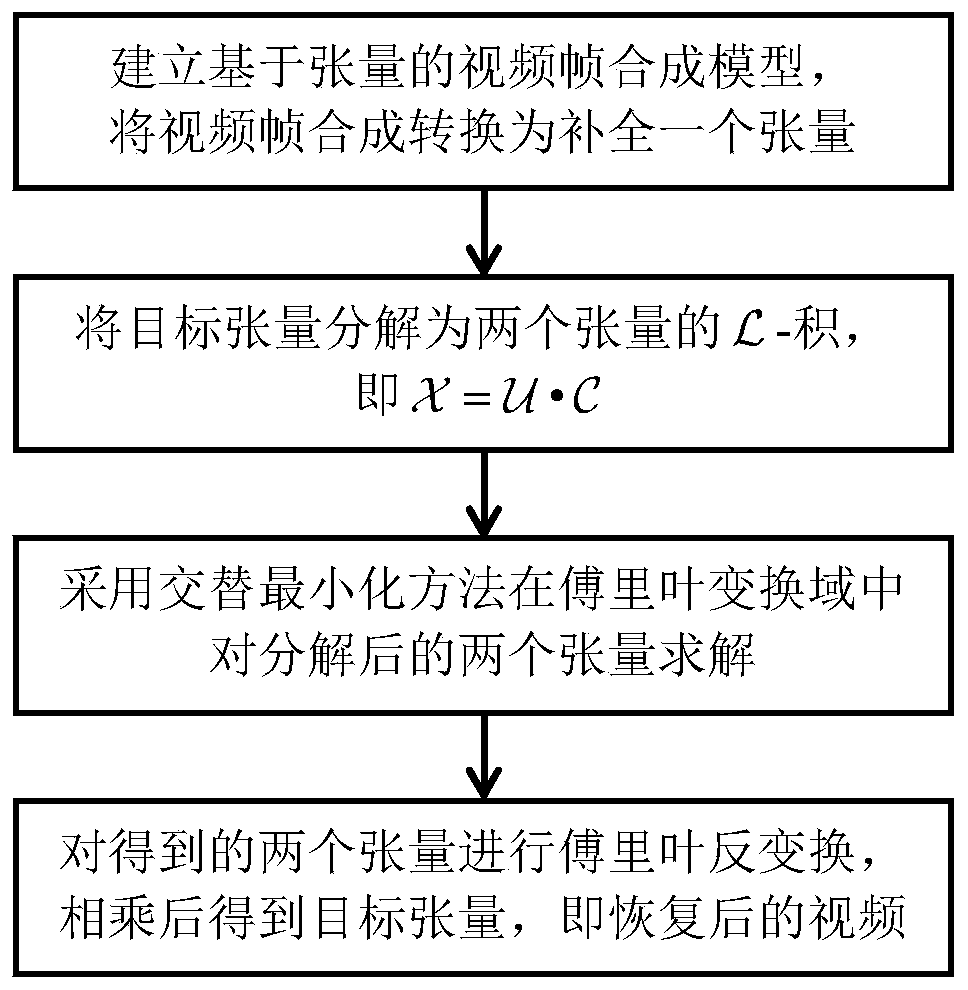
[0026] In view of the above-mentioned status quo, the present invention proposes a tensor-based video frame synthesis method through research and innovation, see figure 1 , including the follow...
Embodiment 2
[0033] The tensor-based video frame synthesis method is the same as in embodiment 1, and the low-rank tubal-rank tensor complement expression for constructing the video frame synthesis described in step 1 is specifically
[0034] 1.1 For a with n 3 full video frame Randomly zero the frames in the video for recovery, or zero the last few frames of the video for prediction, input the video data after randomly zeroing a few frames in the middle or zero the last few frames Ω represents the original video The set of sequence numbers of existing frames in is the projection tensor on Ω, Indicates the existing video frame data, namely
[0035]
[0036] in for tensor The i-th frontal slice of , i.e., the i-th frame of the full video, has size n 1 ×n 2 , for tensor The ith frontal slice of , 0 is n 1 ×n 2 A matrix of all 0s, indicating that the frame is missing; |Ω| indicates the video The number of existing frames in , then there are n 3 - |Ω| frames need...
Embodiment 3
[0043] The video frame synthesis method based on tensor is the same as embodiment 1-2, the target tensor described in step 2 decomposed into two sizes of with The third-order tensor of - product, specifically
[0044] 2.1 The target tensor in step 1 Decomposed into In the form of , where the third-order tensor third rank tensor Represents two third-rank tensors - product, for any two third-order tensors with defined as [n 1 ] means 1 to n 1 collection of Represents a rank three tensor The tube in row i and column j, Represents a linear transformation, namely the Fourier transform, yes The inverse transformation of , * indicates the multiplication between corresponding elements.
[0045] 2.2 The video frame synthesis is converted into the following form
[0046]
[0047] That is, according to the minimum Frobenius norm, solve the third-order tensor with
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More