

Speech enhancement method using stacked multiscale modules
A speech enhancement and multi-scale technology, applied in speech analysis, instruments, etc., can solve the problems of time-domain signal modeling difficulty and modeling difficulty, so as to improve direct processing ability, improve speech enhancement effect, and good noise resistance Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

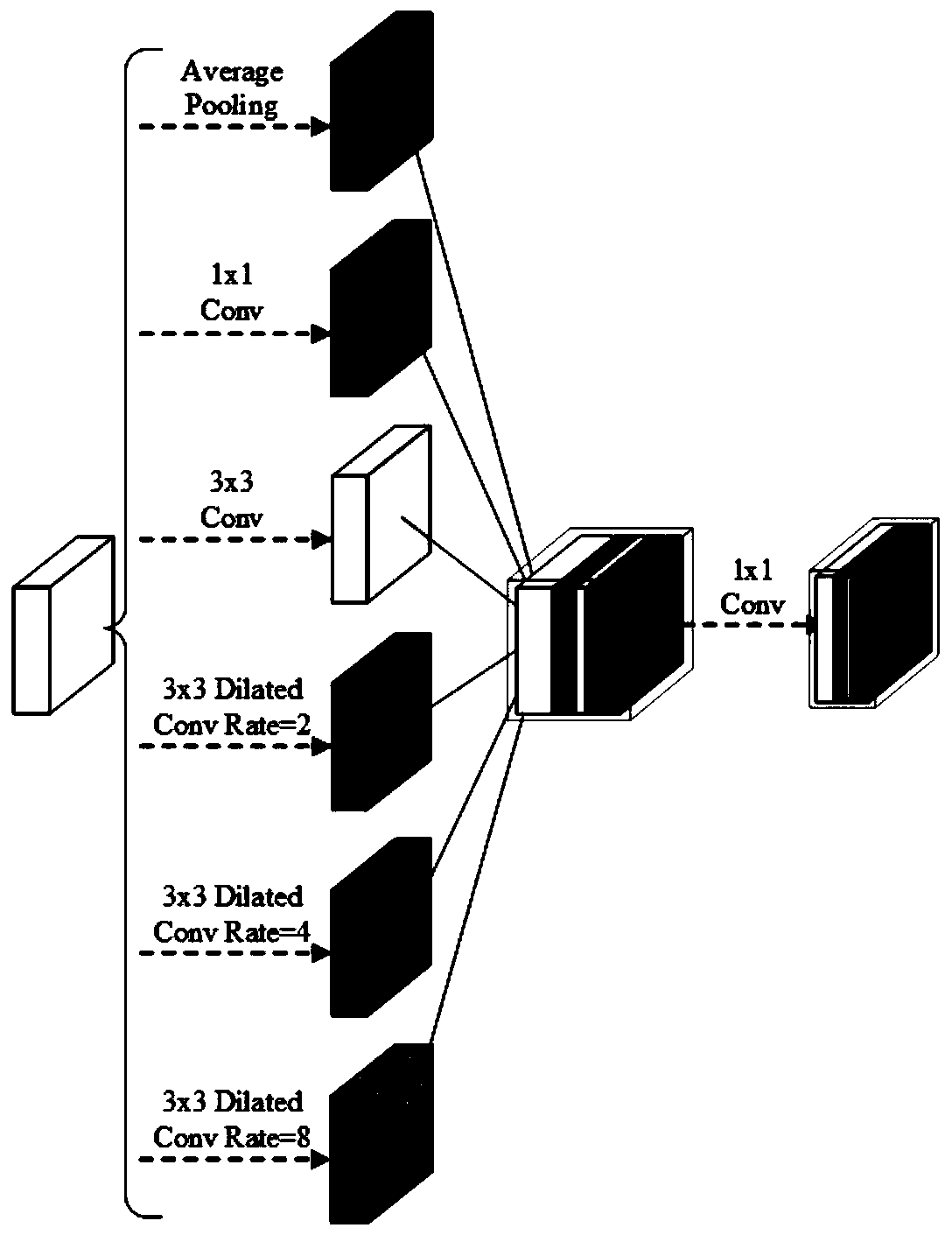
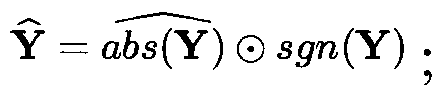
Examples
Embodiment
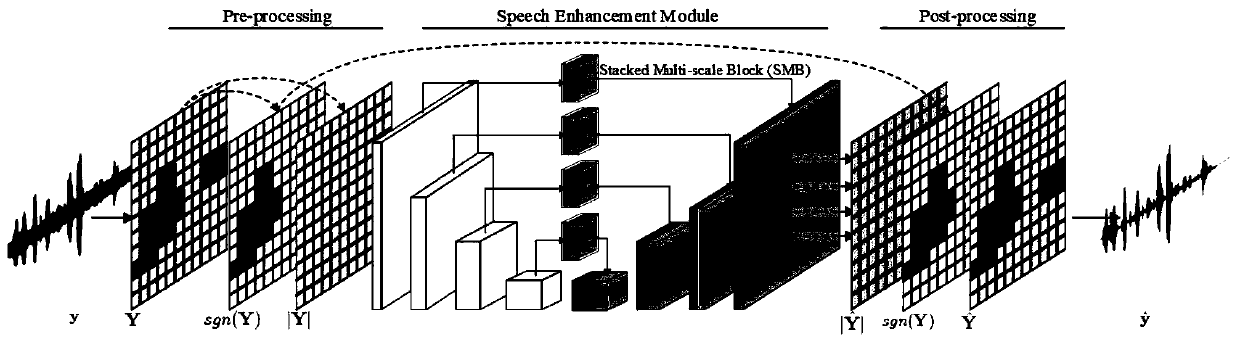
[0051] see Figure 1-2 , the present invention provides a technical solution: an end-to-end speech enhancement method using stacked multi-scale modules, comprising the following steps:
[0052] S1: Construct a cascaded end-to-end speech enhancement framework and stitch stacked multi-scale modules into the network structure;
[0053] S2: In the preprocessing stage, the time domain signal is transformed into two-dimensional features;
[0054] S3: Use the speech enhancement module to enhance the two-dimensional features;
[0055] S4: In the post-processing stage, the enhanced feature representation is transformed into a one-dimensional time-domain signal by decoding synthesis.
[0056] The end-to-end speech enhancement framework proposed by the present invention includes speech time domain signal preprocessing, speech enhancement module and target speech synthesis post-processing, such as figure 1 shown.
[0057]Assuming that the time-domain clean speech is x and the noise si...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More