

Density clustering method and device based on dynamic grid hash index
A hash index and density clustering technology, applied in the field of data processing, can solve the problems of high space complexity of PDBSCAN algorithm, no incremental clustering algorithm proposed, high time complexity of PDBSCAN algorithm, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
example 1
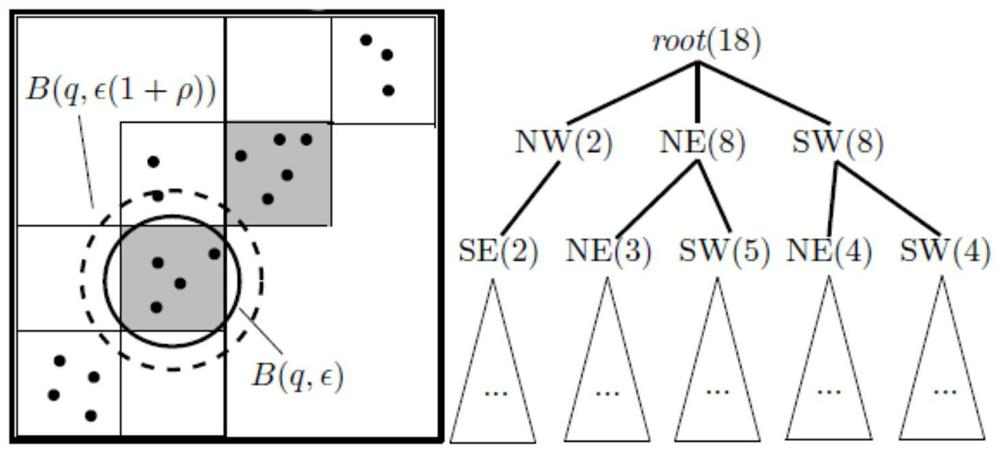
[0111] refer to image 3 , Efficiency comparison between GH-PDBSCAN algorithm and PDBSCAN algorithm
[0112] The experiment part uses four different data types, among which image and abalone are derived from UCI, and the negative values in the two data types are deleted. The other two are artificially synthesized data, as shown in Table 1. The four data types all use the method of Gullo et al. to generate attribute uncertainty data, and each data type includes two forms of random distribution (random) and normal distribution (normal). The test platform is window 7, 32G memory, 32-core CPU, the development tool is Visual studio2012, and the programming language is C++.
[0113]
[0114]
[0115] Table 1
[0116] The efficiency comparison between the GH-PDBSCAN algorithm and the PDBSCAN algorithm needs to be tested separately from the two dimensions of data value range and data volume. The test results are as follows: image 3 shown.
[0117] ima...
example 2
[0153] refer to Figure 4.1 and 4.2 , Incremental GH-PDBSCAN algorithm and GH-PDBSCAN algorithm efficiency comparison
[0154] The GH-PDBSCAN algorithm can handle big data, so this article uses a data volume of 1 million, each data object is three-dimensional spatial data, and specifies the third dimension of each object as an uncertainty attribute. For specific implementation methods, refer to 2008 article by Gullo et al. The experimental method of the Incremental PDBSCAN algorithm proposed in this paper is similar to the experimental method of the Incremental DBSCAN algorithm proposed by Ester et al. in 1998.
[0155] The clustering time of each data object of the GH-PDBSCAN algorithm depends on the time of range search, and the time consumption of clustering n data objects can be recorded as Cost DBSCAN (n), namely
[0156] cost DBSCAN (n)=n (5)
[0157] The number of range searches for the Incremental GH-PDBSCAN algorithm depends on the specific applica...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More