

Cross-modal multi-feature fusion audio and video speech recognition method and system
A multi-feature fusion and speech recognition technology, applied in speech recognition, character and pattern recognition, speech analysis, etc., can solve problems such as being easily affected by complex environmental noise
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
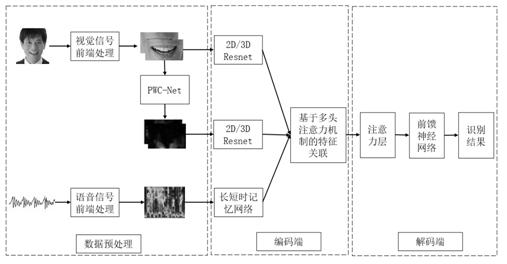
[0035] Such as figure 1 and figure 2 As shown, a cross-modal multi-feature fusion audio-video speech recognition method includes:
[0036] 1) Preprocess the audio data of the speaker to obtain the spectrogram sequence Xa ;Preprocess the video data of the speaker and extract the image sequence of the lip area Xv , extract the lip motion information to obtain the optical flow map sequence Xo ;
[0037] 2) For spectrogram sequences Xa Perform feature extraction to obtain speech timing features Ha , for the lip region image sequence Xv Perform feature extraction to obtain lip timing features Hv , for the sequence of optical flow maps Xo Perform feature extraction to obtain time series features of lip movement Ho ;
[0038] 3) Use the multi-head attention mechanism to target the obtained speech timing features Ha , lip timing characteristics Hv Timing characteristics of movement between lips Ho Calculate the association representation in different modalitie...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More