

Crowd evacuation simulation method in dynamic environment based on deep reinforcement learning
A technology of reinforcement learning and dynamic environment, which is applied in the field of crowd simulation and computer simulation, can solve the problems of exponential increase in computational complexity, huge storage space and indexing time, and low accuracy of crowd, so as to increase behavior randomness and crowd behavior The effect of randomness enhancement
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

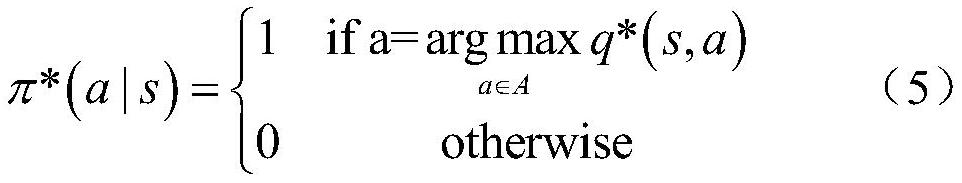
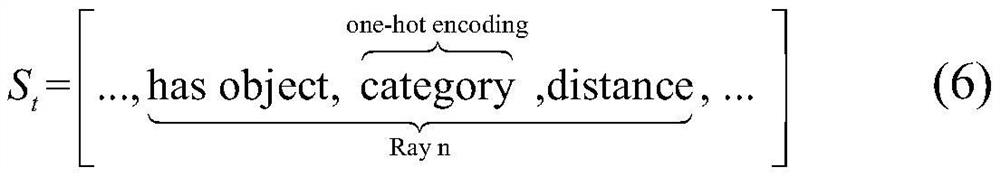
Examples
Embodiment Construction
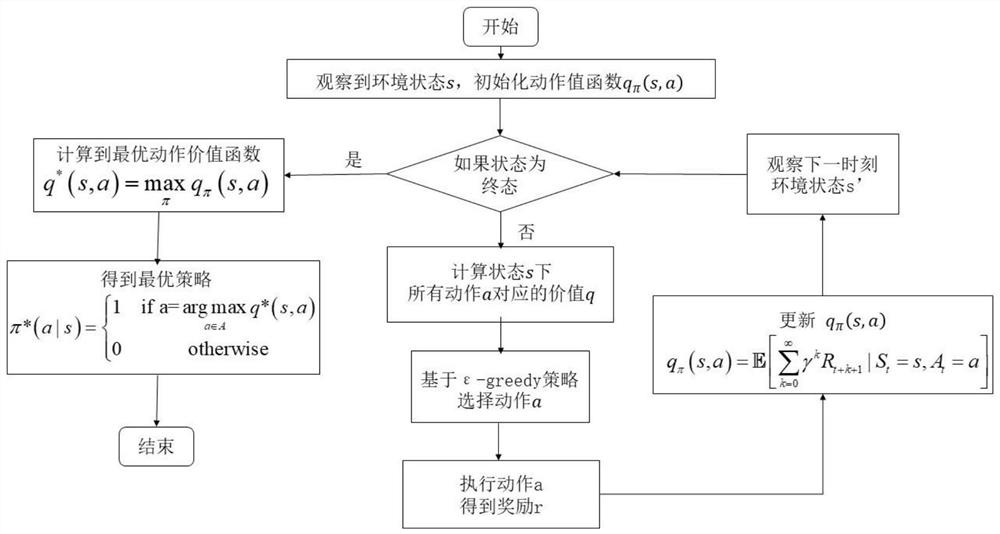
[0030] 1) Deep reinforcement learning algorithm
[0031] Such as figure 1 As shown, the present invention provides a crowd evacuation simulation method based on deep reinforcement learning in a dynamic environment, which includes:
[0032] The crowd is a multi-agent system. For a single pedestrian agent, a deep neural network is used to approximate the mapping function from state to action as the behavior controller of the agent. By observing the dynamic environment state, the pedestrian agent uses the The mapping function makes behavioral decisions and takes corresponding actions from the action space. The goal of a reinforcement learning agent is the process of finding an optimal policy. The so-called strategy refers to the mapping from state to action, which is often represented by the symbol π. A policy refers to the probability distribution of an agent's actions in a given state: Where S is a finite state set; A is a finite action set; is the state transition proba...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More