

Comprehensive position coding method for vocabulary sequence data
A technology of sequence data and encoding method, which is applied in the field of natural language processing, can solve problems such as ineffectiveness and irreplaceable data features.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

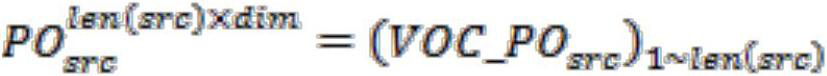
Examples
Embodiment
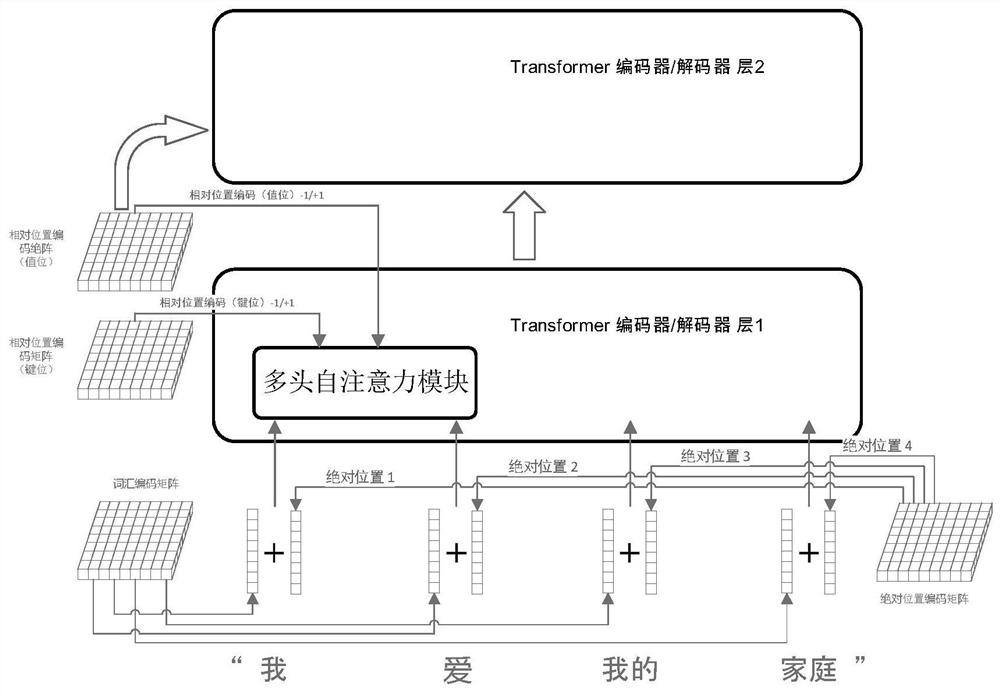
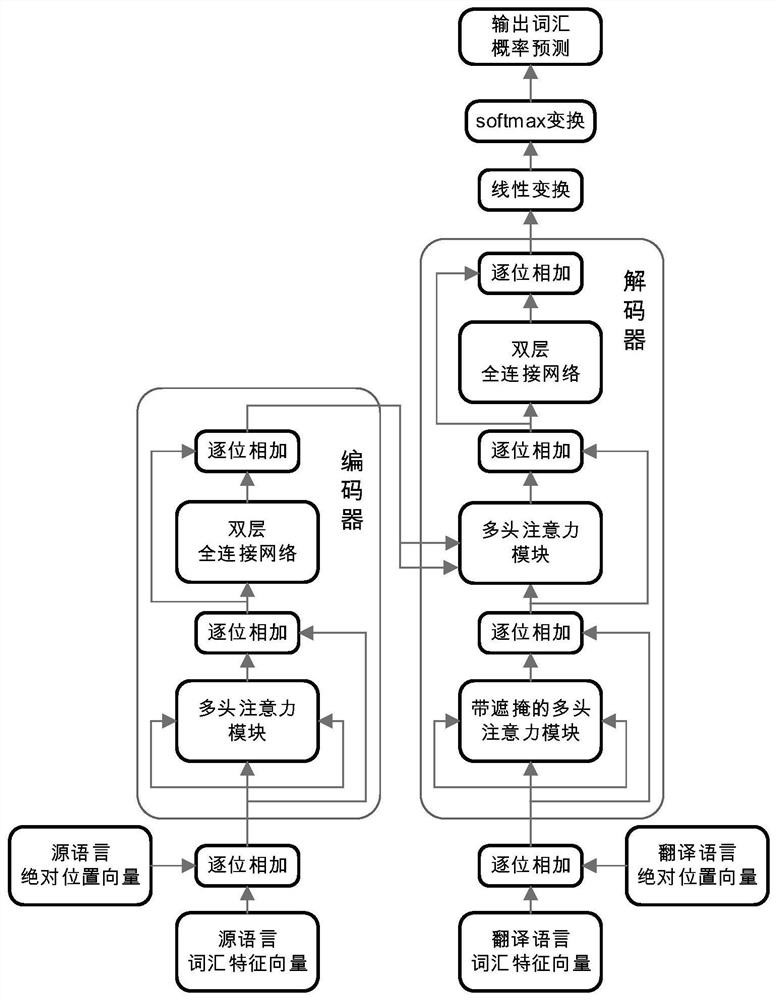
[0074] In order to enable those skilled in the art to better understand the solution of the present invention, the technical solution of the present invention will be clearly and completely described below in conjunction with an application example of the present invention in a neural machine translation model Transformer. The present invention emphasizes the complete calculation process of the position coding method and the calculation details of the model, which can be referred to the attached figure 1 and 2 to understand.
[0075] The calculation process of the Transformer model in the training phase and the testing phase is as follows. All input, output and intermediate variables will be marked with their size and shape when they appear for the first time, and will not be marked with superscripts when they appear again. Variables without superscripts are scalars:
[0076] Each pair of parallel corpus, that is, source input - target input, is a pair of vocabulary sequence...
Embodiment 2
[0143] The testing process of the trained Transformer model is as follows:
[0144] S1': The test data is in the same form as the training data, that is, a pair of source input and target input vocabulary sequences.
[0145] S2': Same as the training process of the model, input the source input sentence into the encoder of the trained Transformer model to get the final encoder output X N .
[0146] S3': set For the final output of the Transformer model generated in the previous round, the Extract the serial number of the element with the largest value in each row of , and locate it in the target input vocabulary code dictionary VOC tgt in the corresponding vocabulary, and sequentially extract their feature vectors to form the output Pred of the Transformer model i×dim .
[0147] S4': Take the feature vector representing start as the first row, Pred i×dim The line numbers of other lines in the line are incremented by 1, and we get Test_Input (i+1)×dim , which is input ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More