Power grid transmission line defense method based on multi-agent deep reinforcement learning
A power transmission line and reinforcement learning technology, applied in neural learning methods, based on specific mathematical models, reasoning methods, etc., can solve the problem of increased action space, deep reinforcement learning methods in action space are not scalable, and existing methods are no longer applicable And other issues
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
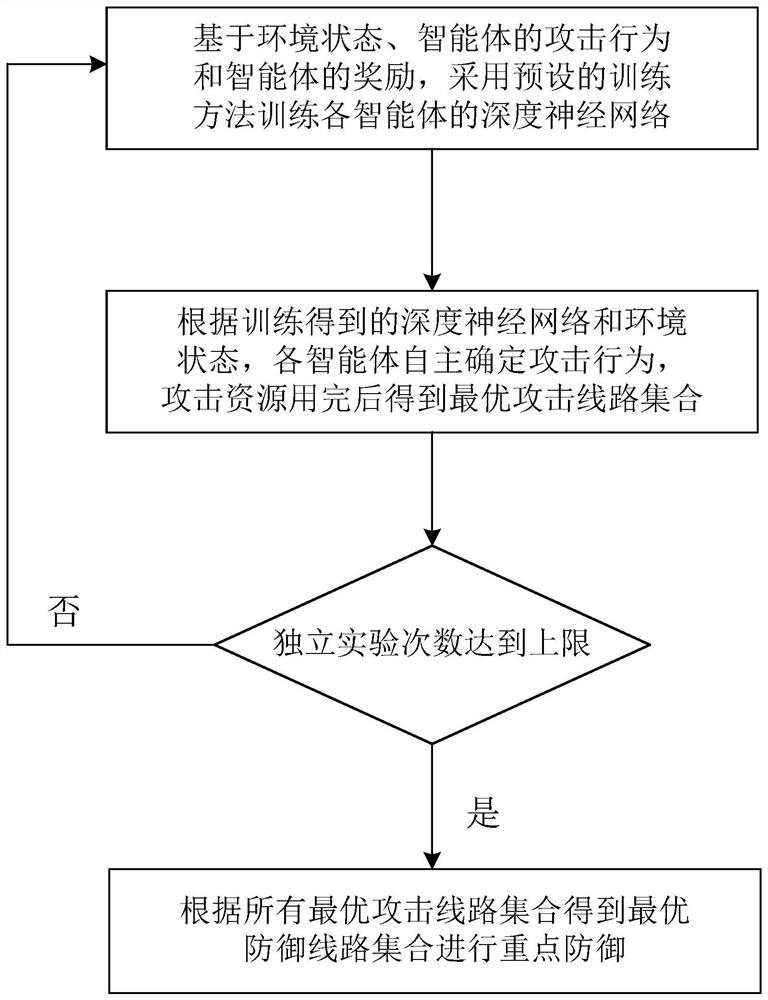
[0077] Such as figure 1 As shown, the embodiment of the present invention provides a method for resisting attacks on power grid transmission lines in the present invention, and the method includes the following steps:
[0078] Based on the environment state, the attack behavior of the agent and the reward of the agent, the deep neural network of each agent is trained using the preset training method;
[0079] According to the trained deep neural network and the state of the environment, each agent independently determines the attack behavior, and the optimal attack line set of each agent is obtained after the attack resources are used up;
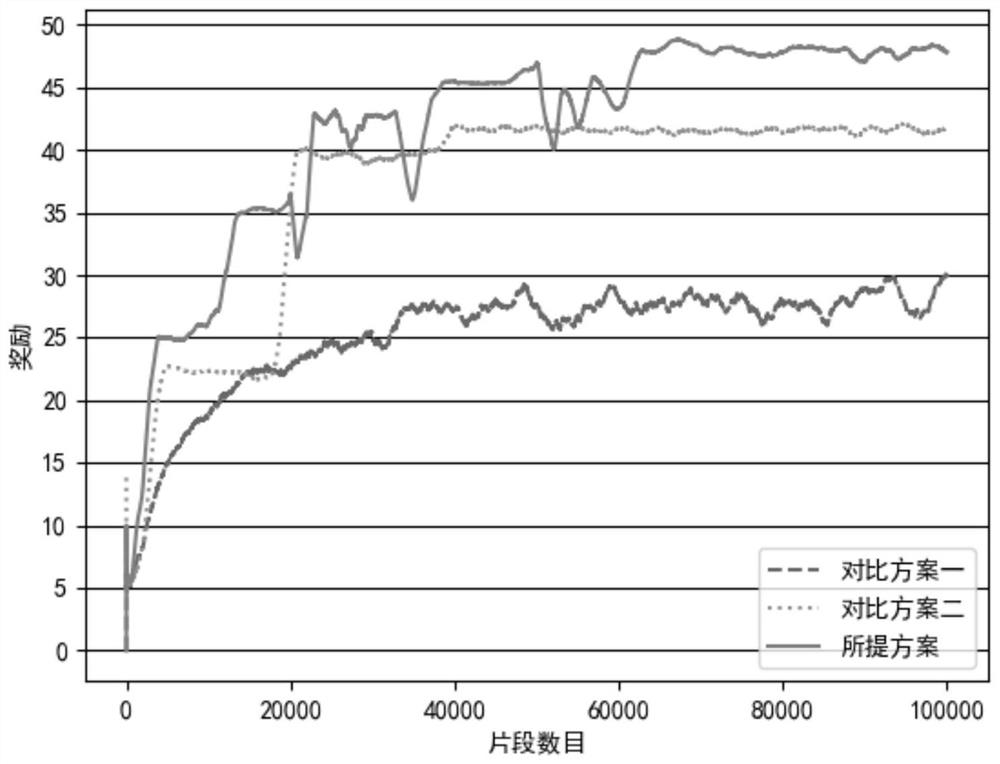
[0080] The above steps are repeated several times, and the optimal defense line set is obtained according to the optimal attack line set of each agent for key defense. In the case of the same attack resources, the power grid transmission line defense method proposed by the present invention can effectively reduce the losses caused by multi...
Embodiment 2
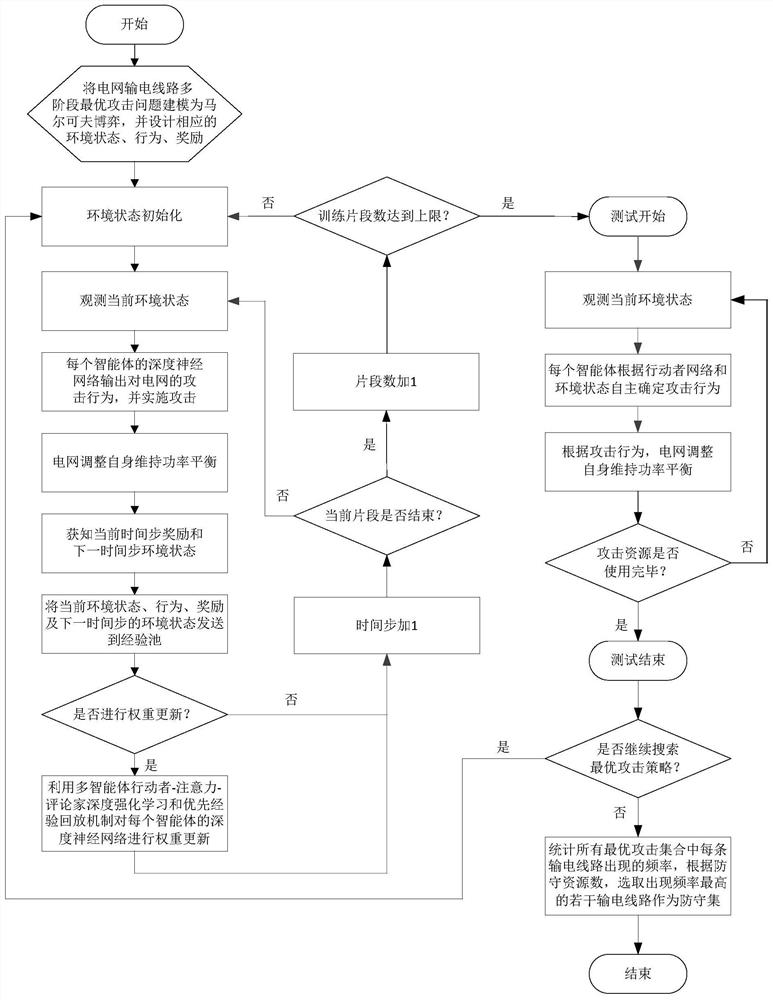
[0129] This embodiment is a specific application scenario based on a multi-agent deep reinforcement learning-based power grid transmission line defense method provided in Embodiment 1. The following embodiments are only used to illustrate the technical solution of the present invention more clearly, and not to This limits the protection scope of the present invention.
[0130] In this embodiment, the IEEE 118 bus is used as the simulation of the grid environment, and the grid includes 186 transmission lines in total.
[0131] Step 1: Model the multi-stage optimal attack problem of power grid transmission lines as a Markov game, and design the corresponding environmental states, behaviors and rewards.
[0132] Specifically, a Markov game is a multi-agent extension of the Markov decision process, and a Markov game can be defined by a series of states, behaviors, state transition functions, and rewards. The objective function of the multi-stage optimal attack problem on power gr...
Embodiment 3
[0189] The embodiments of the present invention provide that the present invention provides a power grid transmission line defense system based on multi-agent deep reinforcement learning, including:
[0190] Training module: used to train the deep neural network of each agent based on the environment state, the attack behavior of the agent and the reward of the agent, using the preset training method;
[0191] Test module: used to determine the attack behavior of each agent independently according to the deep neural network and environment state obtained through training, and obtain the optimal attack line set of each agent after the attack resources are exhausted;
[0192] Defense module: used to obtain the optimal defense line set according to the optimal attack line set of each agent for key defense.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More