Proprietary domain corpus model construction method, computer equipment and storage medium
What is AI technical title?
AI technical title is built by Patsnap AI team. It summarizes the technical point description of the patent document.
A construction method and corpus technology, applied in computer equipment and storage media, and in the field of corpus model construction in proprietary fields, to achieve the effects of reducing training costs, high accuracy, and improving accuracy
Active Publication Date: 2021-04-06
达而观数据(成都)有限公司
View PDF13 Cites 2 Cited by
Summary
Abstract
Description
Claims
Application Information
AI Technical Summary
This helps you quickly interpret patents by identifying the three key elements:
Problems solved by technology
Method used
Benefits of technology
Problems solved by technology
[0006] In order to solve the various deficiencies of the general language model in the document NLP task of a specific industry domain, the present invention proposes a method for constructing a corpus model in a specific domain, computer equipment and storage media, and constructs a corpus model in a specific domain by using data enhancement means To improve the accuracy of downstream NLP tasks
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View more
Image
Smart Image Click on the blue labels to locate them in the text.
Viewing Examples
Smart Image
Click on the blue label to locate the original text in one second.
Reading with bidirectional positioning of images and text.
Smart Image
Examples
Experimental program
Comparison scheme
Effect test
Embodiment 1
[0033] This embodiment provides a method for constructing a proprietary domain corpus model, including the following steps:
[0034] Step 1. Corpus collection and preprocessing
[0035] In many industries, such as the financial industry, due to the need for information disclosure, you can find a large number of natural and open PDF files on the Internet, including but not limited to bond prospectuses, prospectuses, investment fund contracts, and equity pledge announcements.
[0036] This step requires parsing and extracting the text in the massive PDF to obtain sufficient pure unsupervised corpus. The specific parsing methods include:
[0037] (1) Maintain the continuity of the text content, divide it by paragraphs, and ensure that the context in the paragraphs is coherent;
[0038] (2) Conversion of traditional and simplified text content, converting all traditional characters into simplified characters;
[0039] (3) The title of the document is taken as a separate paragrap...
Embodiment 2
[0055] This embodiment is on the basis of embodiment 1:
[0056] Suppose a media user uses a crawler to obtain a large number of stock-related documents, and hopes to distinguish which stock each document belongs to through the classification model, and analyze whether it is good or bad.
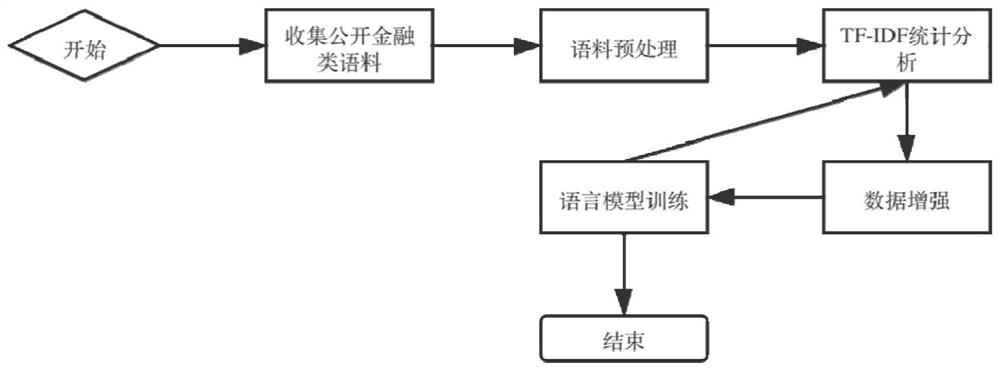
[0057] Correspondingly, this embodiment provides a method for constructing a proprietary domain corpus model, such as figure 1 shown, including the following steps:
[0058] Step 1. Parse all files, extract the plain text information in PDF, and clean and preprocess the obtained text;
[0059] Step 2. Use the TF-IDF statistical model to analyze the word frequency and inverse frequency of the corpus to obtain proprietary words in the financial field or high-frequency words in specific texts;
[0060] Step 3. According to the high-frequency words in step 2, find the paragraph where it is located, and copy the paragraph 2 times in any part of the text;
[0061] Step 4. Carry out the pre-trai...
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
PUM
Login to View More
Abstract
The invention discloses a proprietary domain corpus model construction method, computer equipment and a storage medium. The method comprises the following steps of 1, corpus collection and preprocessing: obtaining sufficient pure unsupervised corpora through data cleaning; 2, word frequency and inverse text frequency index analysis: identifying words with relatively high importance degree in the pure unsupervised corpus through a TFIDF statistical method; 3, data enhancement: enhancing sentences where the high-frequency words extracted in the step 2 are located; and 4, language model training: modeling the pure unsupervised corpus enhanced in the step 3 through an XLNet model to generate a proprietary domain corpus model. According to the method, the accuracy, recall rate and F1 value of a classification task can be obviously improved through the proprietary domain corpus model generated by the proprietary corpus after data enhancement. According to the method, the pre-training process of the language model can be greatly shortened, and meanwhile, the resource consumption in the pre-training process is greatly reduced.
Description
technical field [0001] The invention relates to the technical field of natural languageprocessing, in particular to a method for constructing a corpus model in a proprietary field, computer equipment and a storage medium. Background technique [0002] There are a lot of text processing tasks in the daily operation of enterprises, and the types of documents are very diverse. Each type of document has a relatively fixed format, specification, and fixed collocation. There are a large number of text natural languageprocessing application scenarios in the daily text documentprocessing work of enterprises, such as text word segmentation, document format type classification, text sentiment analysis, key information extraction, contract document review, document similarity calculation, etc. [0003] Currently in academia and industry, most NLP tasks are pre-trained language models, such as n-gram, Bert, GPT and their variants. The essence of the idea of pre-training is to let ...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
Application Information
Patent Timeline
Application Date:The date an application was filed.
Publication Date:The date a patent or application was officially published.
First Publication Date:The earliest publication date of a patent with the same application number.
Issue Date:Publication date of the patent grant document.
PCT Entry Date:The Entry date of PCT National Phase.
Estimated Expiry Date:The statutory expiry date of a patent right according to the Patent Law, and it is the longest term of protection that the patent right can achieve without the termination of the patent right due to other reasons(Term extension factor has been taken into account ).
Invalid Date:Actual expiry date is based on effective date or publication date of legal transaction data of invalid patent.



 Login to View More
Login to View More  Login to View More
Login to View More