Neural network accelerator, convolution operation implementation method and device and storage medium
A convolution operation and neural network technology, applied in biological neural network models, physical implementation, complex mathematical operations, etc., can solve the problem of long time required to complete reasoning
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
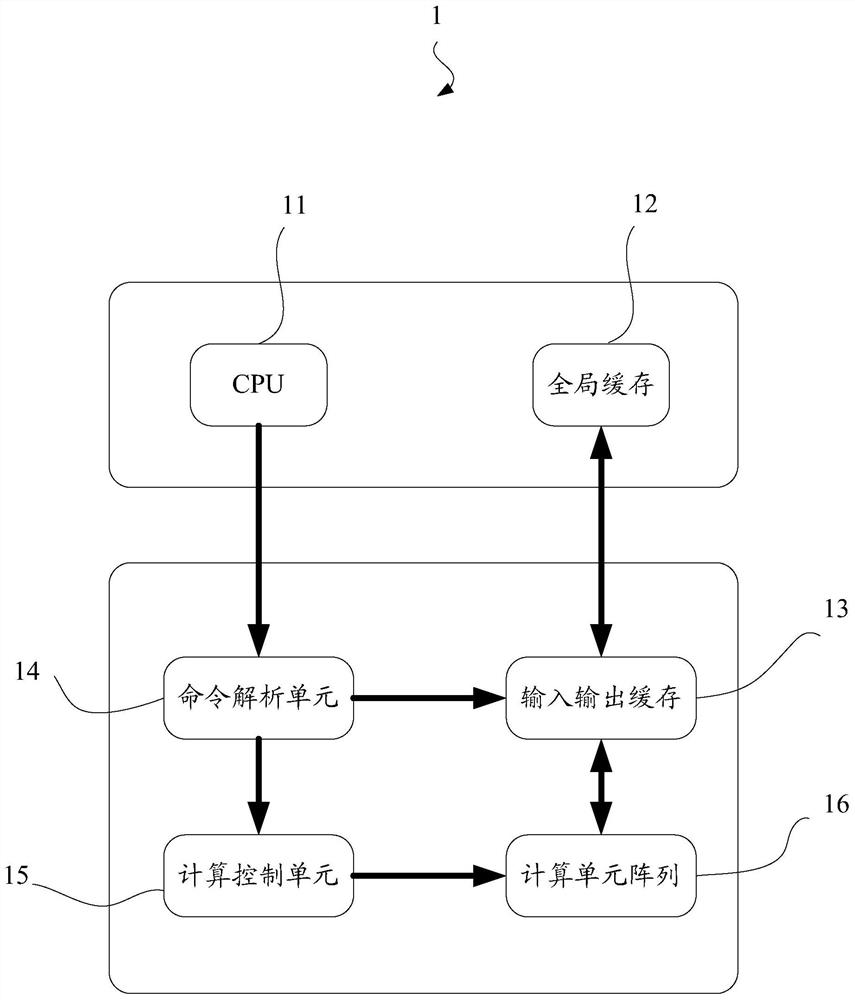
[0038] In order to improve the processing efficiency of neural network processing and reduce the calculation amount of neural network convolution operation, this embodiment provides a neural network convolution operation implementation method. Before introducing the neural network convolution operation implementation method, this embodiment first introduces A neural network convolution operation implementation device capable of implementing the neural network convolution operation implementation method, please refer to figure 1 :
[0039] The neural network convolution operation implementation system 1 includes a CPU 11 , a global cache 12 and a neural network accelerator 10 , wherein the neural network accelerator 10 includes an input and output cache 13 , a command parsing unit 14 , a calculation control unit 15 and a calculation unit array 16 .
[0040] Wherein, CPU 11 is connected by communication with command analysis unit 14, and CPU 11 can send control instructions to c...
Embodiment 2
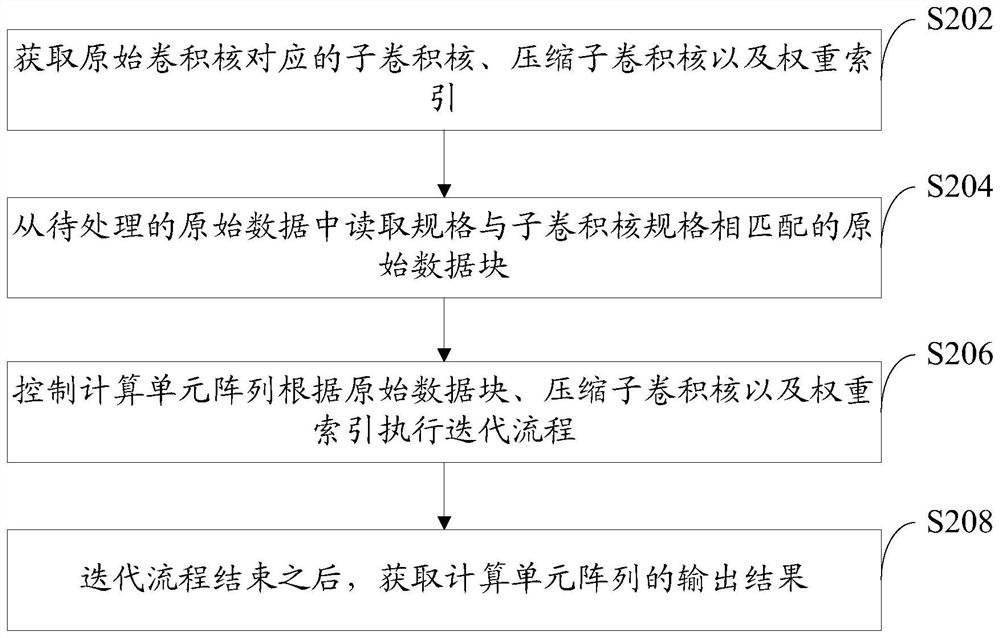
[0077] This embodiment will continue to introduce the neural network convolution operation implementation method and device provided by the present invention, please refer to Figure 7 :
[0078] exist Figure 7 The shown neural network convolution operation implementation system 7 also includes a CPU 71 , a global cache 72 and a neural network accelerator 70 . However, different from Embodiment 1, in this embodiment, the neural network accelerator 70 not only includes an input-output cache 73, a command parsing unit 74, a computing control unit 75, and a computing unit array 76, but also includes a Winograde (Winograd ) conversion unit 77. The Winograde conversion unit 77 is arranged between the input-output cache 73 and the calculation unit array 76, and it is used to convert the compressed sub-convolution kernel and the original data block into In the Winograde domain, the data in the compressed sub-convolution kernel and the original data block transferred to the Winogr...
Embodiment 3
[0109] This example will combine Figure 7 or Figure 8 The shown neural network convolution operation implementation system and some examples continue to introduce the neural network convolution operation implementation provided in the foregoing embodiments:
[0110] [weight conversion]
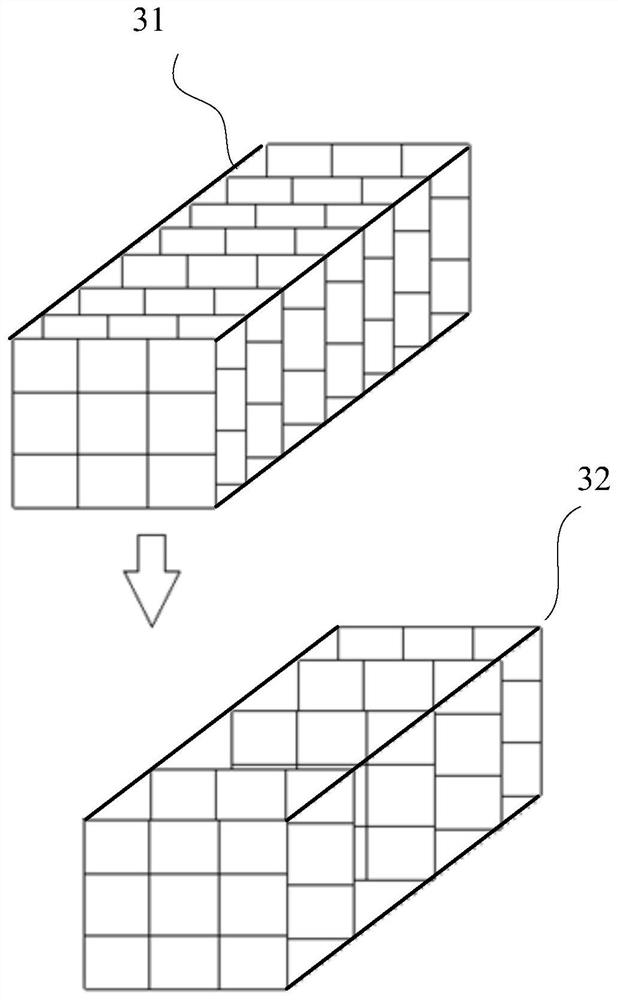
[0111] Figure 10 A schematic diagram of weight compression using a compiler is shown:
[0112] The compiler is divided into a segmentation module 101 and a compression module 102. After processing by the two modules, the original convolution kernel becomes a compressed sub-convolution kernel and weight index.
[0113] For the convolutional neural network, since the convolution kernel is generally a three-dimensional structure, the weights in the convolution kernel can be pruned into a form in which the same channel C is 0 through training, which can further reduce the weight in the weight index. content, to improve compression efficiency, the following uses the 3×3 original convolution ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More