

Task-oriented dialogue strategy generation method
A task-oriented and task-oriented technology, applied in neural learning methods, biological neural network models, instruments, etc., can solve problems such as model collapse, falling into a local optimal state, and failure to benefit, and achieve the effect of wide application value
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0054] In order to have a clearer understanding of the technical features, purposes and effects of the present invention, specific implementations are now described in detail.
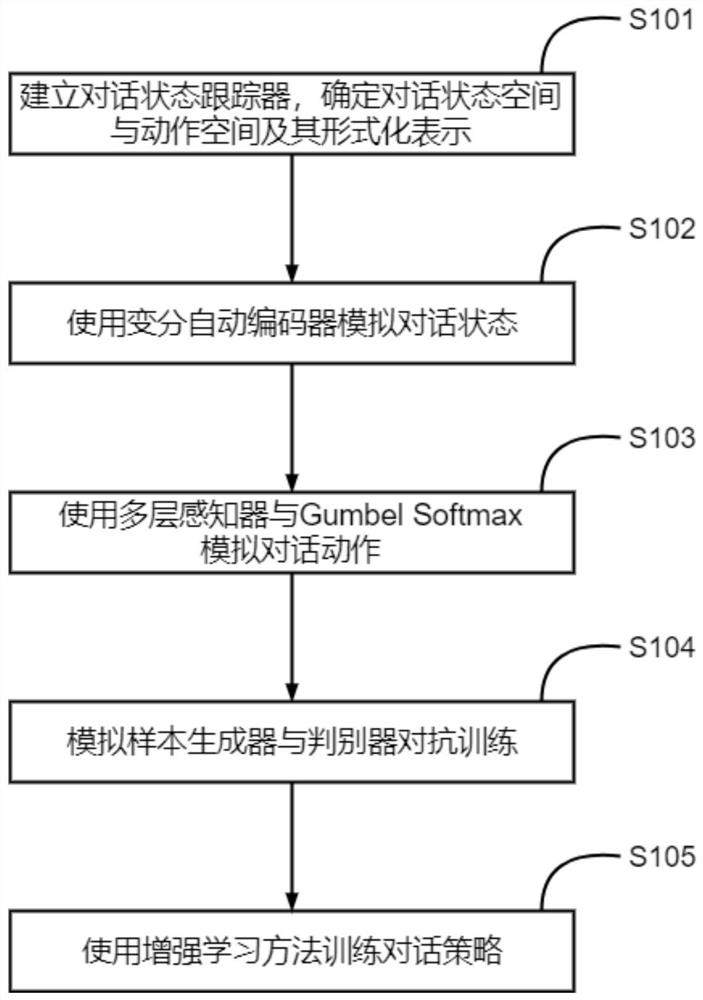
[0055] Such as figure 1 As shown, the task-oriented dialog strategy generation method, the specific steps are as follows:
[0056] S101) Establishing a dialog state tracker, determining a dialog state space and an action space and their formal representations;
[0057] The dialogue state tracker is used to record the slot filling status of the dialogue process, including the information slot given by the user and the request slot representing the user's request. Each slot in each field maintains and updates a confidence vector;
[0058] At each time step t in the dialogue, the information collected by the dialogue state tracker forms a structured representation, that is, the dialogue state St, which is a high-dimensional binary vector, and its content includes the following:
[0059] 1) The embedded ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More