

Large-scale unbalanced diabetes electronic medical record parallel classification neighborhood evidence Spark method
A technology of electronic medical records and diabetes, which is applied in the field of intelligent processing of medical information, can solve the problems of large amount of data, too many attributes of experimental test data, unbalanced parallel classification of electronic medical records of diabetes, and improve efficiency and accuracy. The effect of applying value
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
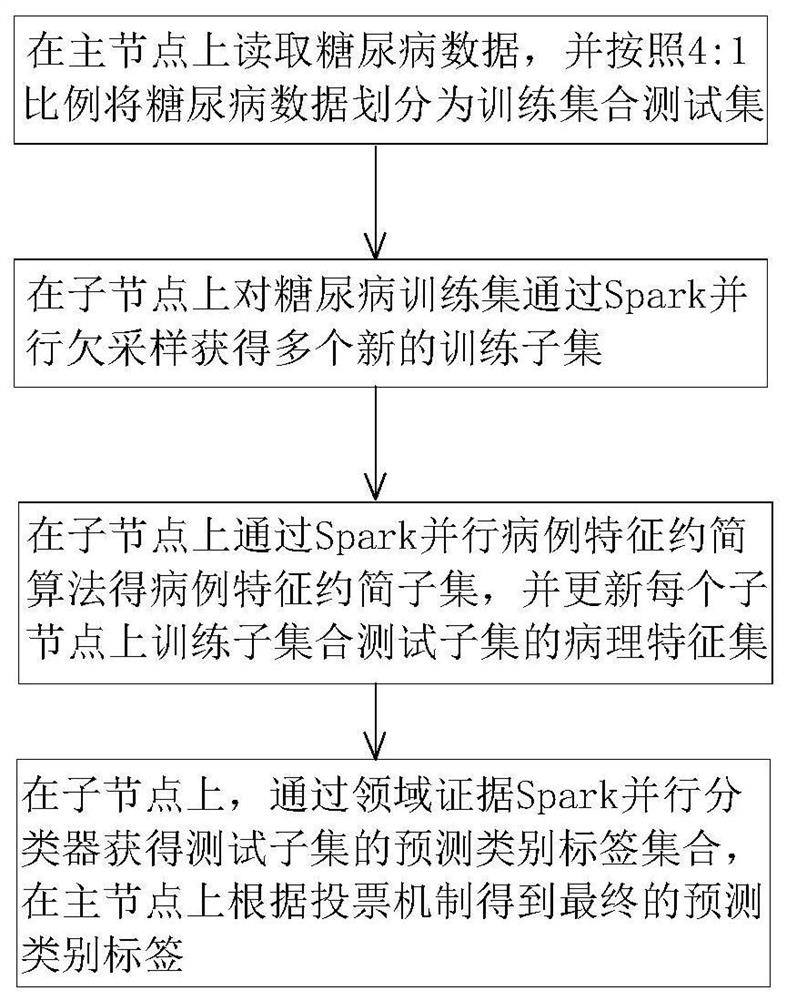
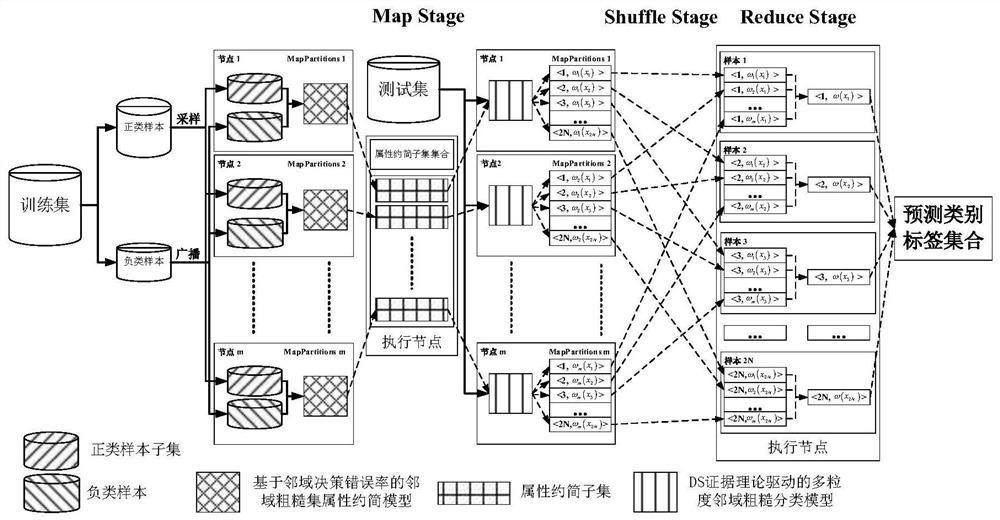
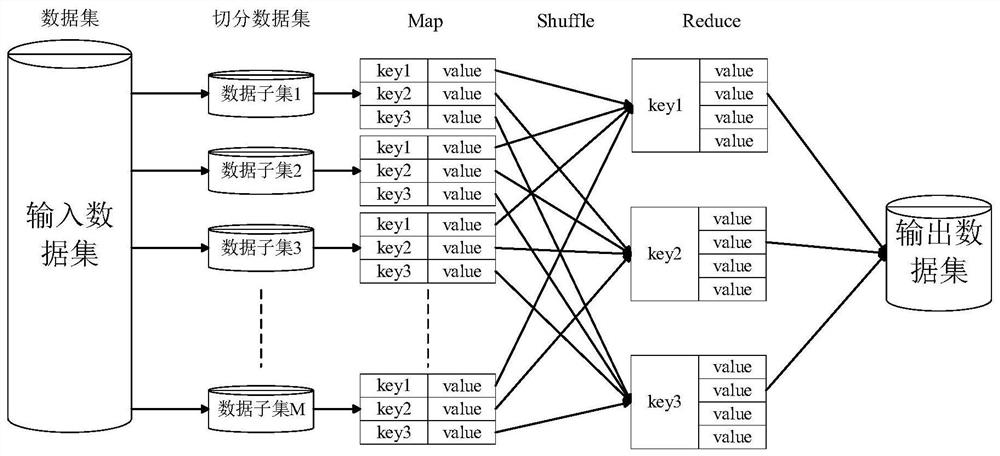
[0062] see Figure 1 to Figure 3 , the present invention provides its technical scheme, a kind of neighborhood evidence Spark method for parallel classification of large-scale imbalanced diabetes electronic medical records, comprising the following steps:
[0063] Step 1. On the master node Master, read the large-scale unbalanced diabetes electronic medical record data set through the Hadoop distributed file system HDFS, and divide the training data set S according to the ratio of 4:1 TR and the test dataset S TE , the training dataset S will be TR Send it to the m child node, and convert the data into a four-tuple decision information system S=, the decision information system S is expressed as follows:
[0064] S=, where U={x 1 ,x 2 ,K,x M} represents the set of patient objects in the diabetes electronic medical record data set, M represents the number of diabetic electronic medical record patients; C={a 1 , a 2 , K, a n} represents the non-empty finite set of pathol...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More