

Audio-driven face animation generation method and system fused with emotion coding
A technology that drives human faces and emotions. It is applied in the field of artificial intelligence and can solve problems such as inability to judge emotional states, high algorithm complexity, and modal particles that cannot fully reflect the speaker's true emotional state.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0044] In order to make the purpose, technical solution and technical effect of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings.
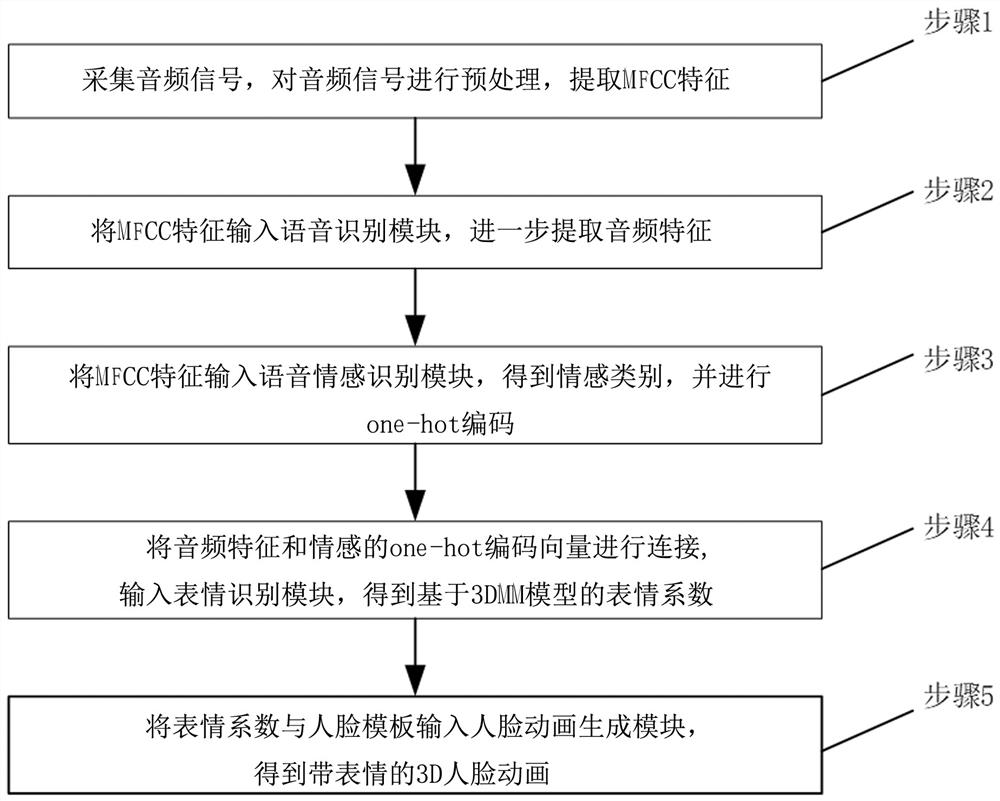
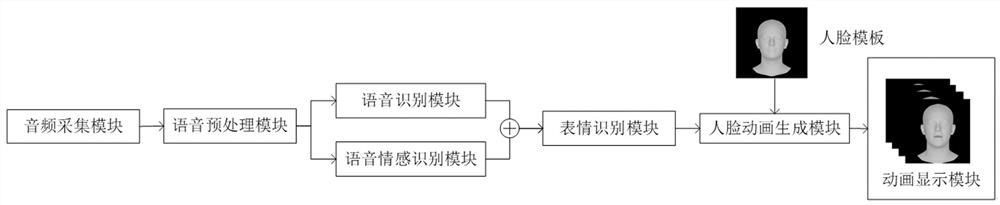
[0045] Such as figure 1 As shown, an audio-driven face animation generation method that incorporates emotion coding includes the following steps:
[0046] Step 1: Preprocess the audio signal and calculate the MFCC features;
[0047] In this embodiment, the sampling rate is set to 16000 Hz, the size of the sliding window is 0.02 s, and the step size of the sliding window is 0.02 s, so the frame rate of the extracted MFCC features is 50 fps.
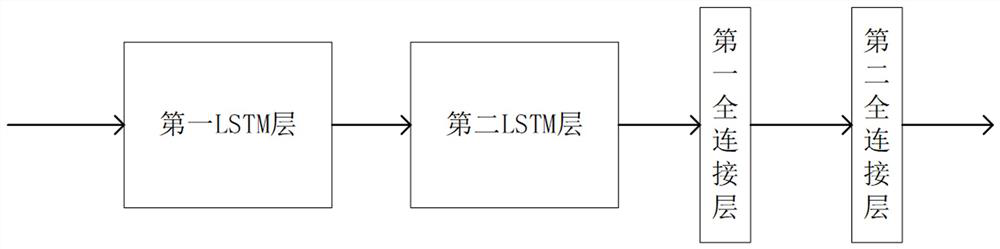
[0048] Step 2: Input MFCC features into the speech recognition module to further extract audio features;
[0049] Because the object of the present invention is to carry out expression estimation for arbitrary audio frequency, therefore extract a generalized audio characteristic, first use speech recognition module to c...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More