

Automatic studying and judging method for emotional tendency of Internet information
A technology of emotional tendency and Internet information, which is applied in the field of automatic research and judgment for the emotional tendency of Internet information, can solve the problems of insufficient generalization effect, poor performance, and low accuracy of the research and judgment model, and achieve strong model generalization ability , improve model performance, and have good robustness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0043] Preprocessing the public opinion corpus data set, the preprocessing steps are:
[0044] Collect the public opinion data with emotional tendency in the public opinion corpus data set, and perform data cleaning on the data;
[0045] Format public opinion data;
[0046] Use Chinese character dictionary files to convert public opinion data on demand;
[0047] Perform multi-process preprocessing on public opinion data.
Embodiment 2
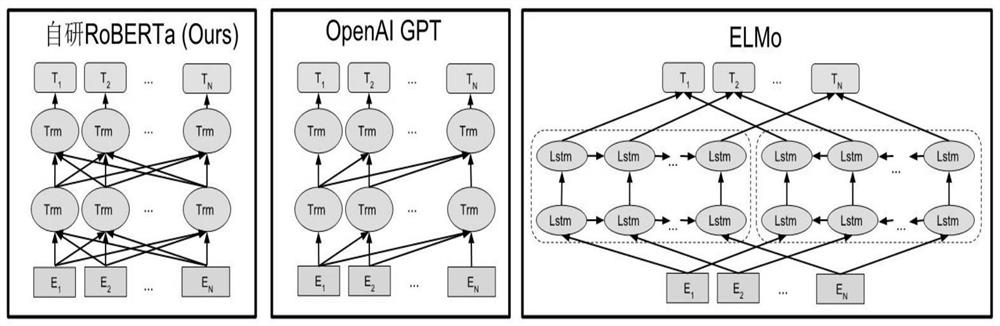
[0049] refer to figure 2 , Differences between pre-training model architectures: BERT uses a bidirectional Transformer. OpenAI GPT uses Transformers from left to right. ELMo uses a concatenation of independently trained left-to-right and right-to-left LSTMs to generate features for downstream tasks. Among the three representations, only the BERT representation is the condition of the joint representation to have both left and right contexts on all layers. Apart from the architectural differences, BERT and OpenAI GPT are fine-tuning methods, while ELMo is a feature-based method.
[0050] In the present invention, the pre-training of the public opinion corpus data set is based on deep learning, and a mixed-precision, multi-machine and multi-GPU training mode is used in the training process. This application uses 160G training public opinion corpus, uses the RoBERTa model to train for one week, batch size is 64, a total of 3 machines each with 8 GPUs (NVIDIA Tesla V100 16G) f...
Embodiment 3
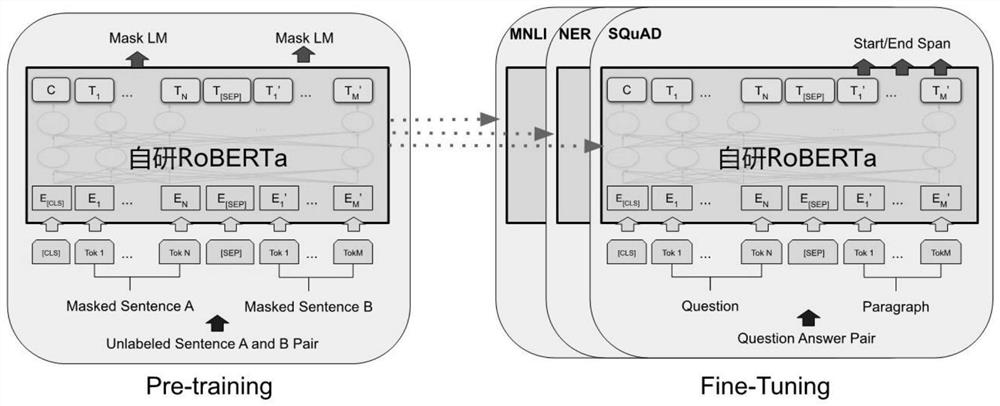
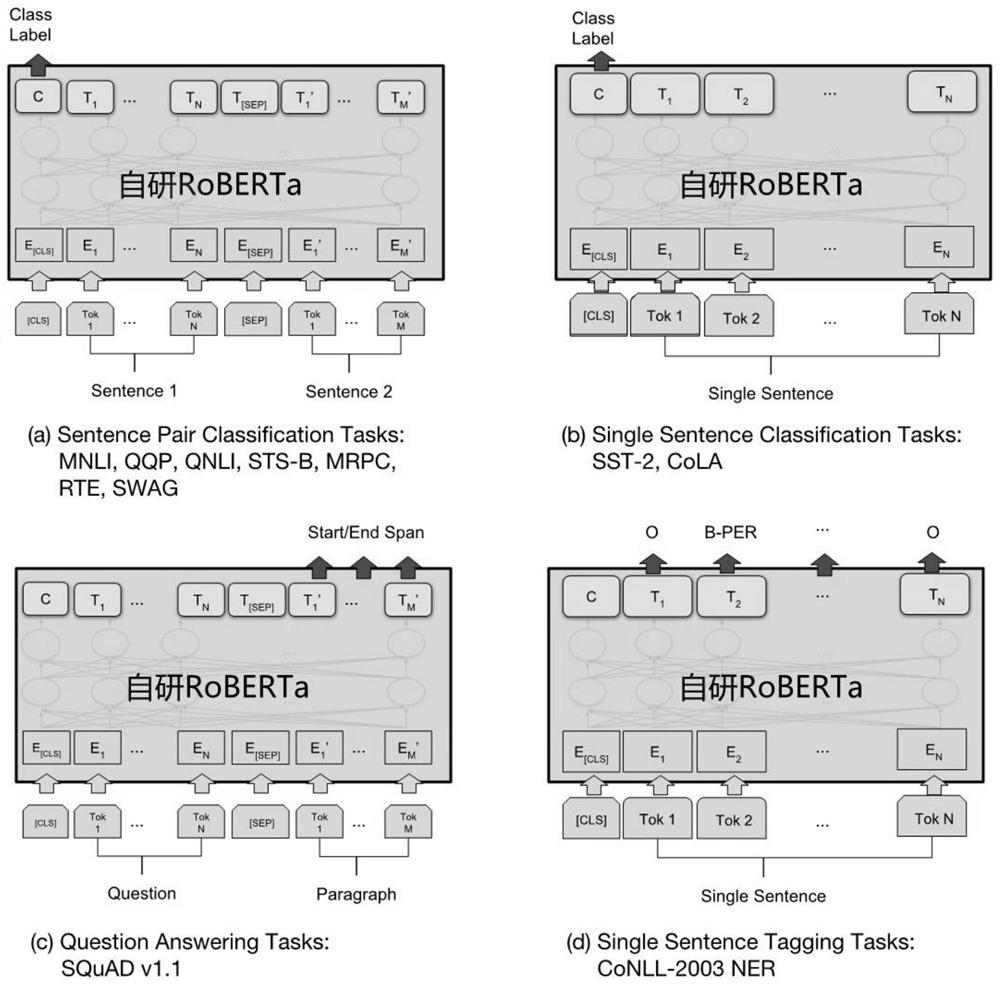
[0057] Such as figure 1 and image 3 , fine-tuning the learning rate parameter of the pre-trained model on the downstream task dataset is 3e-4, the batch size parameter is 64, the epochs parameter is 12, and the mask type is set to fully_visible.
[0058] The RoBERTa model fully pre-trains and fine-tunes BERT. Except for the output layer, the same architecture is used in both pre-training and fine-tuning. Use the same pre-trained model parameters to initialize models for different downstream tasks. During fine-tuning, all parameters are fine-tuned. [CLS] is a special symbol that is added before each input example, and [SEP] is a special delimiter token used to separate questions / answers.
[0059] The prediction task of the final model of this application is as follows:
[0060] Input=[CLS]the man went to[MASK]store[SEP]he bought a gallon [MASK]milk[SEP]
[0061] Label=IsNext
[0062] Input=[CLS]the man[MASK]to the store[SEP]penguin[MASK]are flight ##less birds[SEP]
[...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More