

SELinux strategy optimization method based on knowledge base
An optimization method and knowledge base technology, applied in the field of information security, can solve the problems of manual writing and maintenance of policy files, such as difficulty, error-prone, harmful access, etc., to achieve the effect of improving access control capabilities, reducing writing and maintenance, and improving security.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
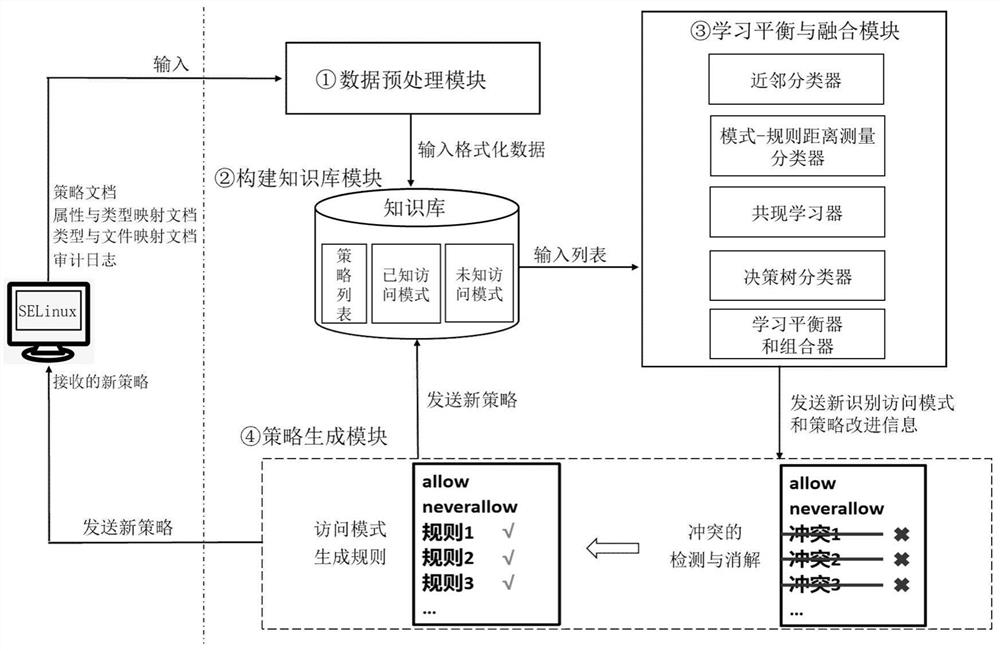
[0028] Specific implementation mode one: the specific process of a kind of SELinux policy optimization method based on knowledge base in this embodiment is:
[0029] Step 1. Obtain data files such as policy collection, audit log, mapping relationship between attributes and types, and mapping relationship between types and full file paths from the SELinux system, and obtain policy collections, audit logs, mapping relationships and types between attributes and types. Data files such as the mapping relationship with the full path of the file are preprocessed to obtain data files such as the policy set after preprocessing, the audit log, the mapping relationship between attributes and types, and the mapping relationship between types and full paths of files;
[0030] Since the format of the data in the file cannot be directly used by subsequent algorithms, data preprocessing is required.
[0031] Step 2. Build a knowledge base based on Step 1;
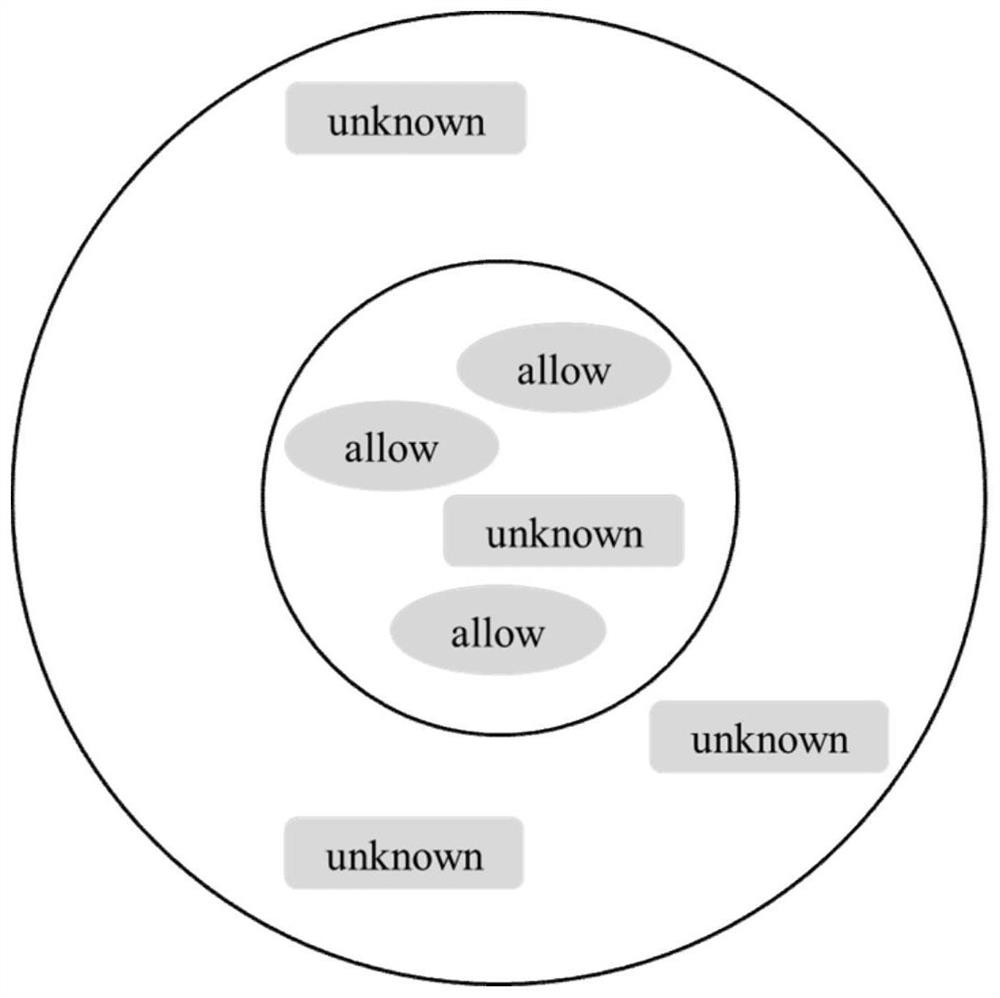
[0032] Step 3. Classify the list o...
specific Embodiment approach 2
[0037] Specific embodiment 2: The difference between this embodiment and specific embodiment 1 is that in the step 1, data files such as the obtained policy set, audit log, mapping relationship between attributes and types, and mapping relationships between types and full paths of files are processed. The specific process of preprocessing is:
[0038] Step 11, data cleaning;
[0039] Step 12, extracting the TE rules of the strategy set based on step 1;
[0040] Step 13, processing the mapping relationship based on step 12;
[0041] Step 14: Generate an access pattern based on Step 13.
[0042] Other steps and parameters are the same as those in Embodiment 1.
specific Embodiment approach 3
[0043] Specific implementation mode three: the difference between this implementation mode and specific implementation mode one or two is that the data cleaning in the step one by one; the specific process is:
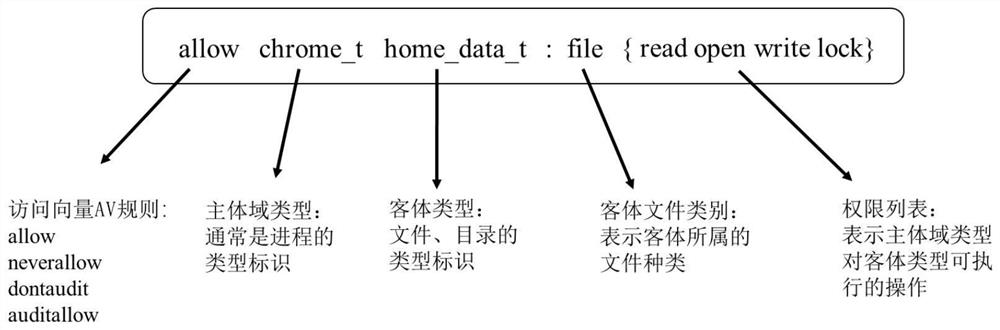
[0044]The policy sets, audit logs, and mapping files directly exported from the SELinux system contain a large amount of data irrelevant to policy analysis and optimization. In order to eliminate the impact of these data on subsequent policy classification, the data irrelevant to this algorithm will be cleaned up. For deleting data with missing values in the audit log, removing log entries whose type (type) in the audit log is not equal to the access vector cache (AVC, Access Vector Cache) type (indicating that the AVC (Access Vector Cache, access vector cache) Cache rejected system requests), remove type transition rules (type_transition) related in the policy set (the relevant ones are the rules starting with type_transition, such as: type_transition user_t passwd_e...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More