

Method and device for automatically identifying web crawlers
A technology of web crawler and automatic identification, applied in the field of network security
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

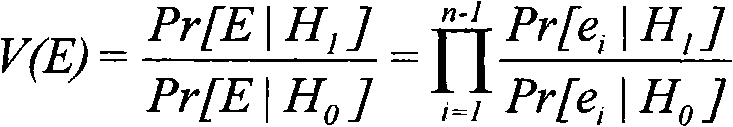
Examples
Embodiment 1
[0058] Embodiment 1, a method for automatically identifying a webpage crawler, based on the observed webpage request sequence to determine whether the operation of the remote host r is a webpage crawler, including:
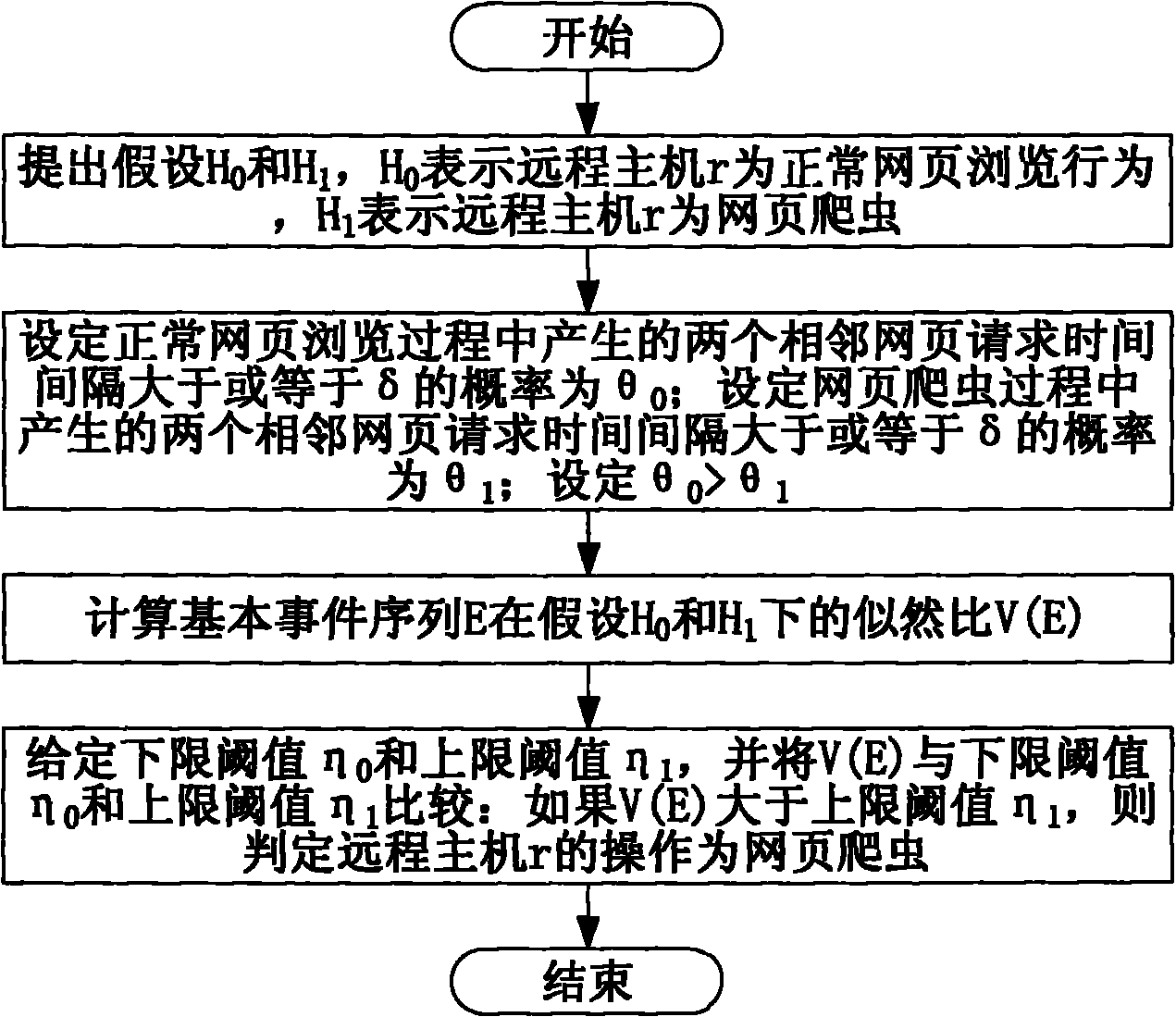
[0059] Obtain the web page request from the remote host r to the Web server s within a period of time, judge whether the time interval of each adjacent web page request is greater than or equal to a predetermined adjacent web page request time interval threshold δ, and whether each judgment result meets the preset condition, to determine whether the operation of the remote host r is a web crawler.
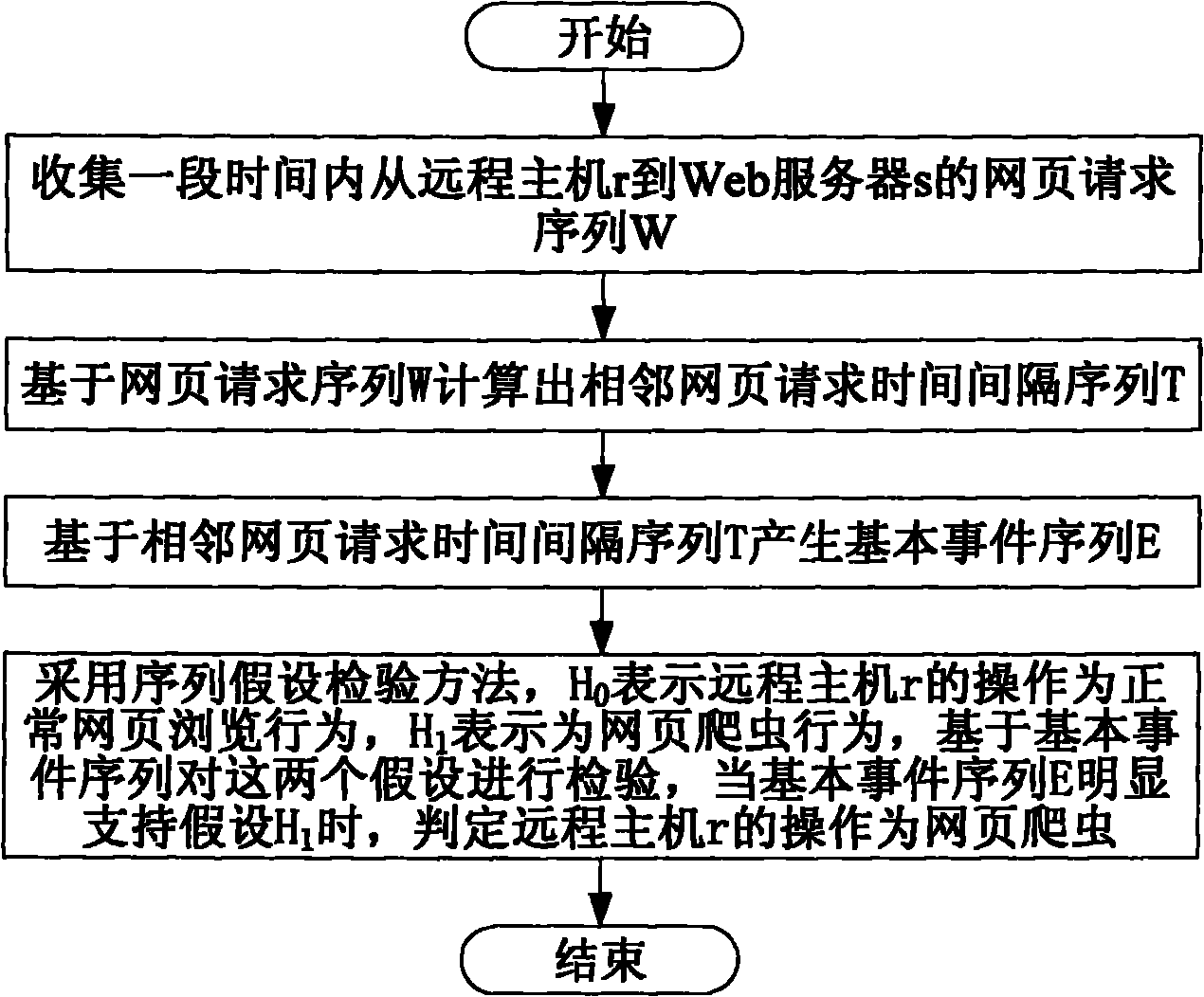
[0060] Such as figure 1 As shown, the method specifically includes the following steps:
[0061] A1, collect the web page request sequence from the remote host r to the web server s within a period of time;
[0062] A2, to the collected web page request sequence W from the remote host r to the Web server s including n web page requests (each element in the sequence u...
example 1
[0091] Assume that according to the step A1 of the web crawler automatic identification method, 10 webpage requests from the remote host r to the web server s are collected, and the initiation time of these 10 webpage requests is shown in Table 1.
[0092] Table 1
[0093]
[0094] According to the step A2 of the web crawler automatic identification method, the time interval sequence T of adjacent web page requests with 9 elements is calculated, as shown in Table 2.
[0095] Table 2
[0096]
[0097] According to step A3 of the method for automatically identifying webpage crawlers and the preset threshold value of the time interval between adjacent webpages δ=3000 milliseconds, the basic event sequence E shown in Table 3 is obtained.
[0098] table 3
[0099]
[0100] According to step A4 of web crawler automatic identification method and preset lower limit threshold η0 is 0.132 and upper limit threshold η1 is 7.59, at first calculate the likelihood ratio of basic e...
example 2
[0103] Assume that according to the step A1 of the web crawler automatic identification method, 10 webpage requests from the remote host r to the web server s are collected, and the initiation time of these 10 webpage requests is shown in Table 4.
[0104] Table 4
[0105] Web page request sequence number
[0106]According to step A2 of the web crawler automatic identification method, the time interval sequence T of adjacent web page requests with 9 elements is calculated, as shown in Table 5.
[0107] table 5
[0108] Element number
[0109] According to step A.3 of the method for automatically identifying webpage crawlers and the preset threshold value of the time interval between adjacent webpages δ=3000 milliseconds, the basic event sequence E shown in Table 6 is obtained.
[0110] Table 6
[0111] Element number
[0112] According to the step A.4 of the automatic identification method of webpage crawler and the preset lower limit threshold ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More