

Frequency-domain blind deconvolution method for voice signal
A speech signal and blind deconvolution technology, applied in speech analysis, speech recognition, instruments, etc., can solve problems such as low robustness, slow algorithm search speed, and large signal cross-interference
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

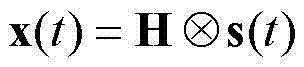
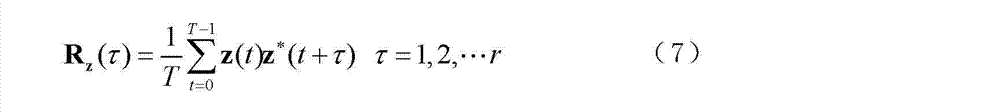
Examples
Embodiment Construction
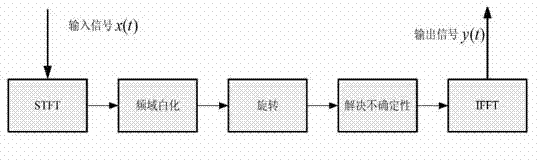
[0047] refer to figure 1 , a voice signal frequency domain blind deconvolution method, the time domain convolution mixed voice signal is transformed into the frequency domain for blind separation, specifically comprising the following steps:
[0048] 1) For the adaptive framing of the original audio file, when the sampling frequency is 16KHz, the frame length is 16ms, and the frame shift is 2ms;
[0049] 2) Fourier transform is performed on the single frame data, and the convolutional mixed signal model is transformed into a linear mixed model; the convolutional mixed model can be expressed as
[0050] x ( t ) = H ⊗ s ( t ) ( means convolution) (1)
[0051] The short-time Fourier transform of the signal can be expressed as
[0052] X ( ω , t ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More