

Data processing method, device and system
A data processing and data technology, applied in the field of data processing, can solve the problems of storage space waste, data redundancy, etc., and achieve the effect of avoiding waste, reducing the moving distance of the magnetic head, and improving the performance of query statistics
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
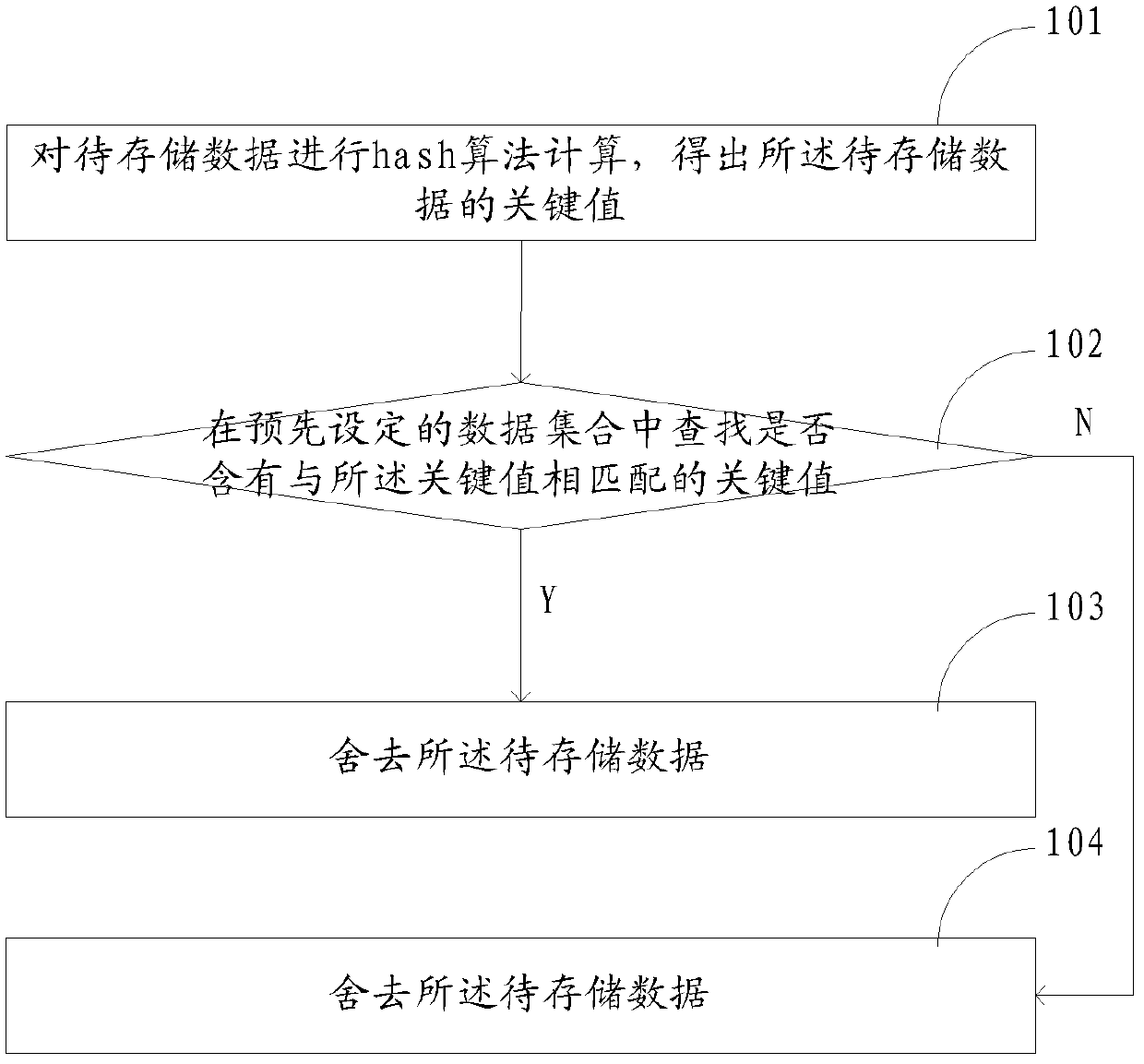
Embodiment 1
[0083] refer to image 3 , which shows a flow chart of Embodiment 2 of a data processing method provided by the present invention. Embodiment 2 of the method of the present invention is based on Embodiment 1 of the method, and further includes the following steps:
[0084] Step 301: Receive a data query request, where the data query request includes query conditions.
[0085] Wherein, after the data query request input by the user is received, the query condition included in the data query request is parsed.
[0086] Step 302: Perform hash algorithm calculation on the query condition to obtain the query key value.
[0087] Wherein, it should be noted that, when calculating the hash algorithm for the query condition, the hash algorithm described in the first method embodiment of the present invention needs to be calculated.
[0088] Step 303: In the key values of the data set, check whether there is a key value matching the query key value, if yes, perform step 304, otherwi...
Embodiment 2
[0146] refer to Figure 9 , which shows a schematic structural diagram of Embodiment 4 of a data processing device provided by the present invention. Based on Embodiment 2 of the device of the present invention, the device may further include:
[0147] The data cache unit 609 is configured to store the data returned by the data search unit 602 into a preset cache data set.
[0148] Wherein, the data search unit 602 stores the returned data as cache data in the cache data set after completing a successful data query. When the receiving unit 605 receives the data query request again, the data cache unit 609 first judges whether the cached data set contains the data corresponding to the data query request, and if so, the data The data requested by the query has been queried, then the data search unit 602 can directly perform data query in the cached data set, if not, it means that the data requested by the data query has not been queried, then the The data search unit 602 perfo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More