

Cardinal number estimating method and cardinal number estimating device under multi-section query condition of big data
A query condition and big data technology, applied in the field of big data computing, can solve the problem of not supporting cardinality statistics, and achieve the effects of reducing calculation errors, improving update efficiency, and high query efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
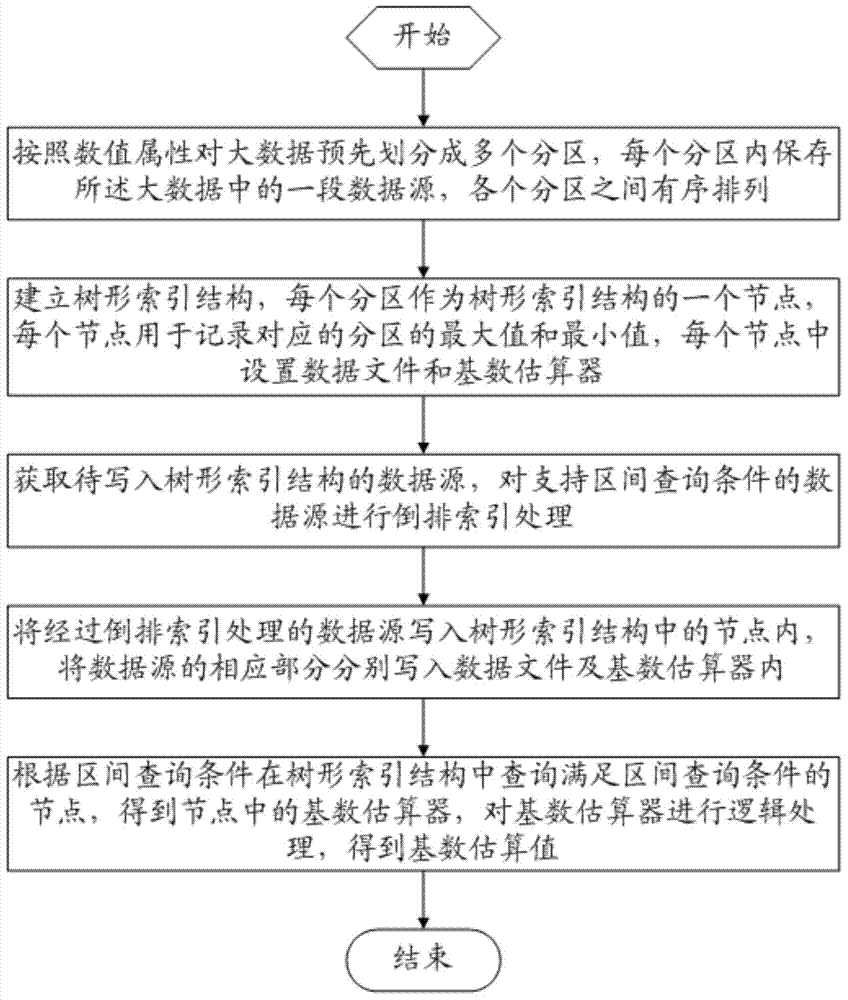
[0046] A cardinality estimation method under the condition of large data multi-interval query, comprising the following steps:
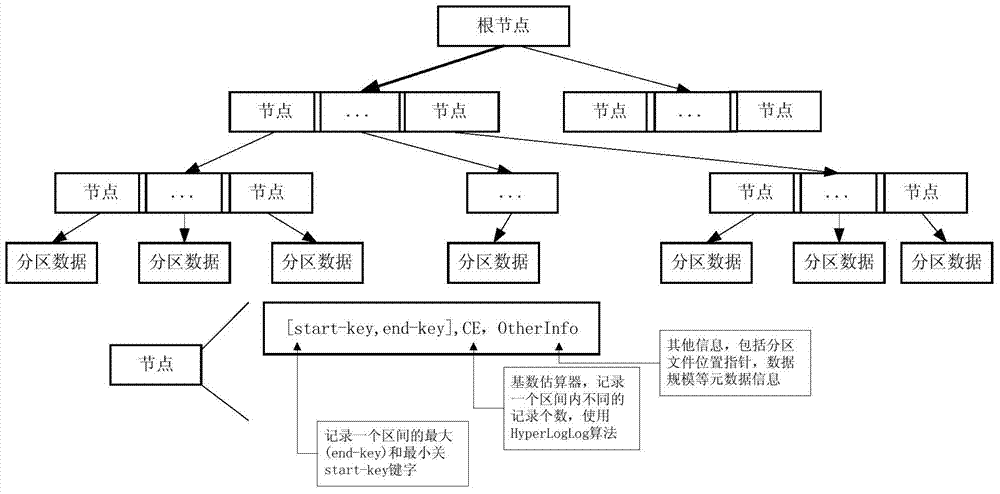
[0047] Step 1: Pre-divide the big data into multiple partitions according to the numerical attributes, store a section of data source in the big data in each partition, and arrange the partitions in an orderly manner;
[0048] Step 2: Establish a tree index structure, each partition is used as a node of the tree index structure, each node is used to record the maximum and minimum values of the corresponding partition, and a data file and a cardinality estimator are set in each node;
[0049] Step 3: Obtain the data source to be written into the tree index structure, and perform inverted index processing on the data source that supports interval query conditions;
[0050] Step 4: Write the corresponding part of the data source processed by the inverted index into the data file and the cardinality estimator respectively;
[0051] Step 5: Query the n...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More