

Data placement method based on distributed cluster
A distributed cluster and data technology, applied in electrical components, transmission systems, etc., can solve problems such as data recovery performance loss, increase data recovery time, and computing power affecting performance, to prevent waste of resources, ensure load balance, and ensure transmission. The effect of efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
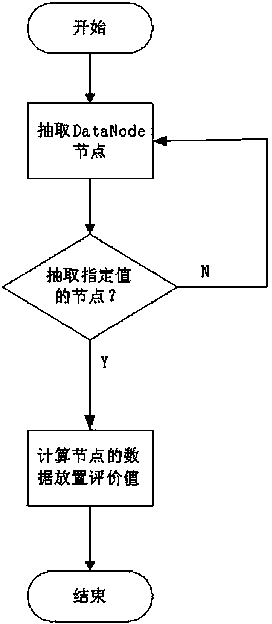
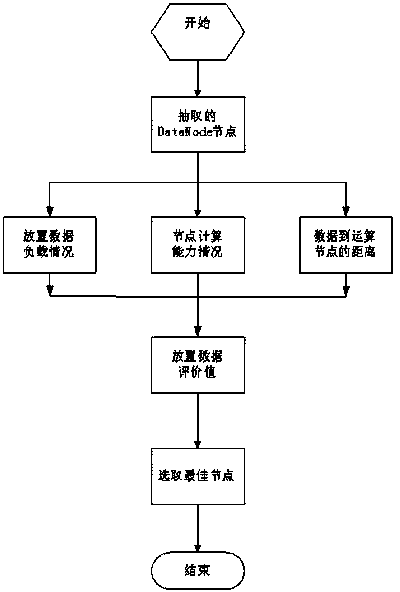
[0029] Referring to the accompanying drawings, a specific example will be used to describe the process of implementing the distributed cluster-based data placement method for the content of the present invention.
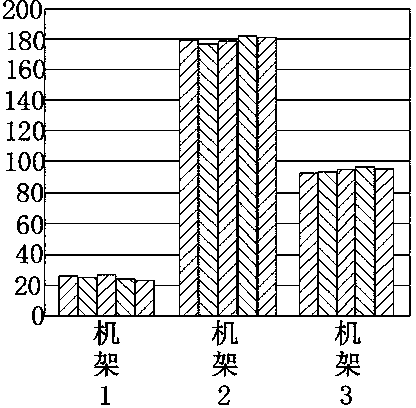
[0030] First, deploy a distributed cluster environment, and install hadoop components on the operating system centos6.3 according to official documents. Then enable the hdfs and mapreduce services. The nodes in rack 1 have ordinary computing capabilities, and the nodes in racks 2 and 3 have fast computing capabilities. There are 5 Datanode nodes in each rack. The flow chart of the data placement method for distributed clusters is as follows figure 1As shown in , when a user submits a data storage request, first select nodes in different racks, and then judge whether the obtained nodes reach the selected fixed value. node. When entering the data placement evaluation module, it is first necessary to calculate the distance information of the current node, the numbe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More