

Hadoop-based data processing method and system
A data processing system and data processing technology, applied in the field of data processing, can solve the problems of intermediate data occupying a large disk space and not being flexible enough, and achieve the effects of reducing network bandwidth, saving CPU time, and reducing disk space occupation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

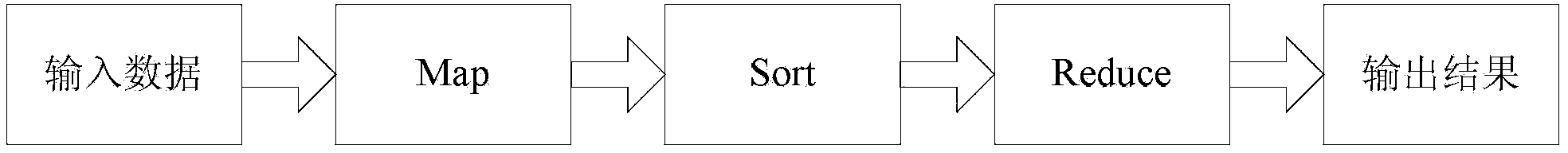
Examples
Embodiment 1
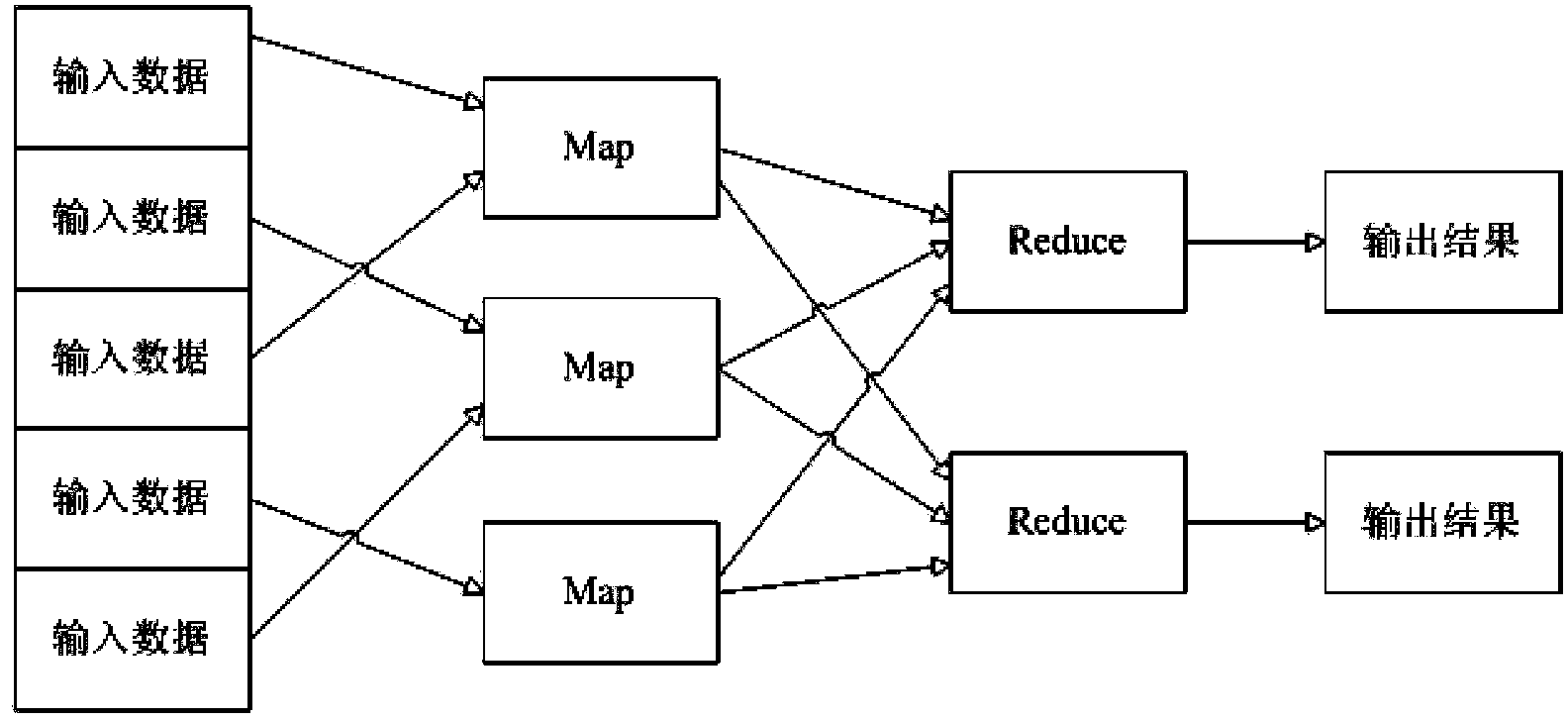
[0036] Figure 2a It is a schematic diagram of data transmission in Hadoop distributed system, Figure 2b is a schematic diagram of data transmission in the present invention, such as Figure 2a with Figure 2b As shown, the main improvement of the present invention is that on the server where the source data is located, before the MAP inputs the data, an intermediate processing module is added to filter unnecessary fields to form a corresponding intermediate file.
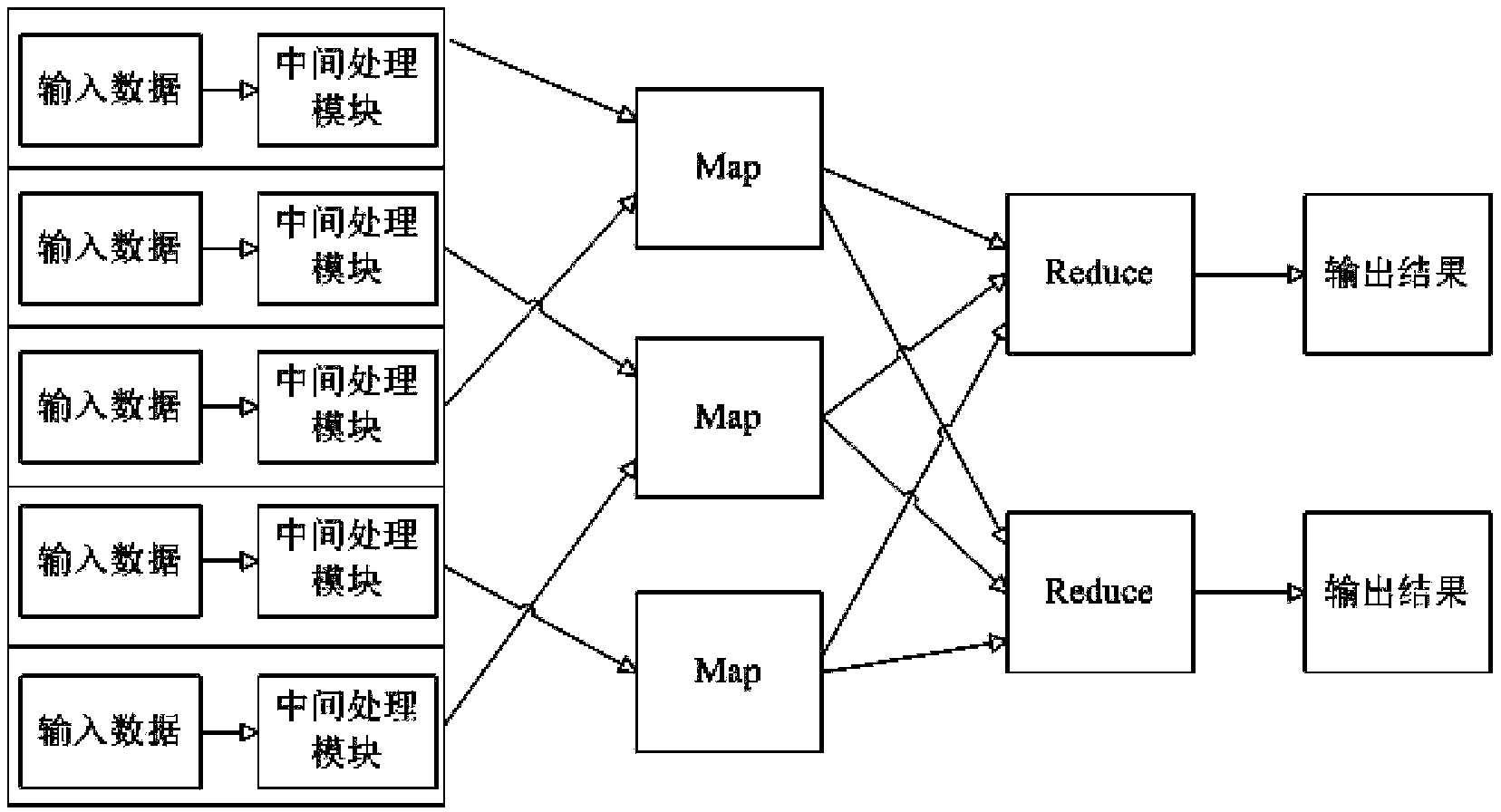
[0037] image 3 It is a schematic diagram of the overall technical solution of the present invention described in this embodiment, as image 3 As shown, the present invention formats the source data before MAP input data, that is, distinguishes each column of data, and after formatting the source data into column structure data, converts the column data into KEY / VALUE through MAP / REDUCE Format, according to the required fields requested by the MAP program, filter unnecessary fields to form a corresponding inte...
Embodiment 2
[0041] Figure 4 It is the flow chart of the Hadoop-based data processing method described in this embodiment, such as Figure 4 As shown, the Hadoop-based data processing method described in this embodiment includes:
[0042] S401. Obtain the source data and demand fields requested by the MAP program, and convert the source data into KEY / VALUE format through MAP / REDUCE;
[0043] The source data includes various data forms such as file data stored on the disk, data in XML format stored on the disk, and / or two-dimensional table data stored in the database.
[0044] S402. Determine whether the source data is column-structured data, if so, execute step S404, otherwise execute step S403;
[0045] S403. Format the source data into column-structured data;
[0046] That is, the source data is formatted into column structure data by distinguishing each column of data. For example, after the source data is formatted, the data is column structure data including fields F1, F2, F3, F4,...
Embodiment 3
[0053] According to the same concept of the present invention, the present invention also provides a Hadoop-based data processing system,
[0054] Figure 5 It is a structural block diagram of the Hadoop-based data processing system described in this embodiment, such as Figure 5 As shown, the Hadoop-based data processing system described in this embodiment is used for data interaction between the data server and the MAP program, wherein the data server includes a data formatting module and a data filtering module, and the MAP program includes data Request module and adaptation recognition module. The modules are introduced as follows:
[0055] Data request module: used to send a data request to the data server, the data request includes the source data of the specified request and the required field of the request;
[0056] The source data includes various data forms such as file data stored on the disk, data in XML format stored on the disk, and / or two-dimensional table d...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More