

Method for improving speech recognition accuracy on basis of voice leading end noise elimination
A speech recognition and front-end noise technology, applied in speech analysis, instruments, etc., can solve problems such as low recognition accuracy and speech endpoint detection errors
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

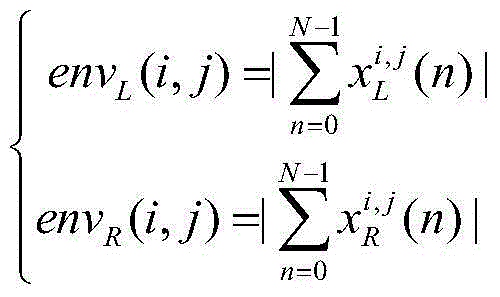
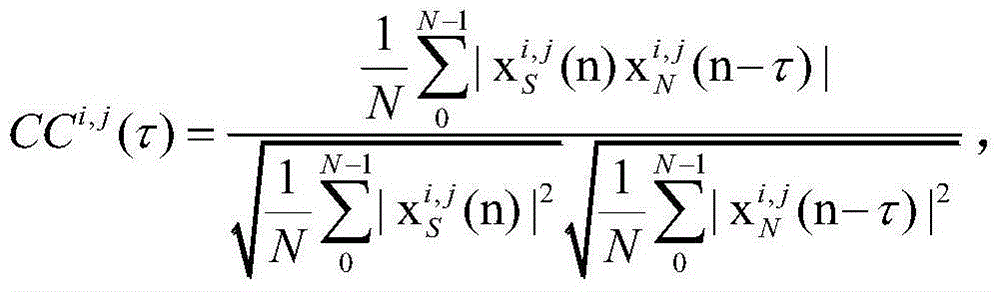
Examples
Embodiment Construction
[0030] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
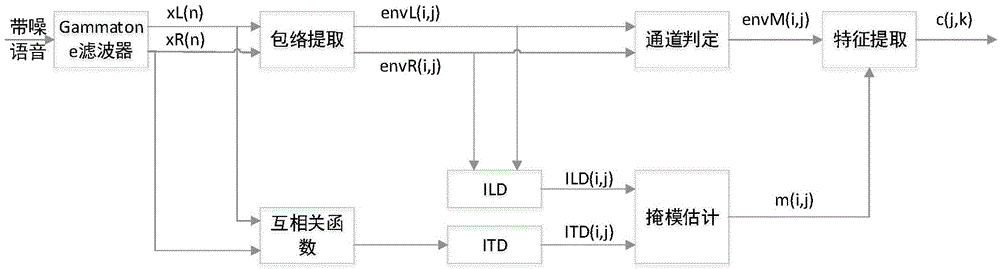
[0031] The working principle of the present invention is as follows: the input noisy speech signal can be regarded as the model of two communication channels inputting pure speech and pure noise respectively, so CASA simulates the effect of human ear, and according to the signal time difference (ITD) of two channel arrivals The sum intensity difference (ILD) is used to determine the sound source, that is, the focus is placed on the pure speech signal. CASA uses ITD and ILD to estimate the mask information of the time-frequency unit (T-Funit) in the time-frequency domain. The information of the T-F mask can indicate where the T-F area is noise and where is speech. Finally, the T-F area containing speech information is used for speech Synthesis, restore "pure" speech.
[0032] Such as figure 1 As shown, the method for improving speech recogniti...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More