

Air combat behavior modeling method based on fitting reinforcement learning
A modeling method and reinforcement learning technology, applied in the field of computer simulation, can solve problems such as long convergence process
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
[0097] Step 1: Perform data sampling.
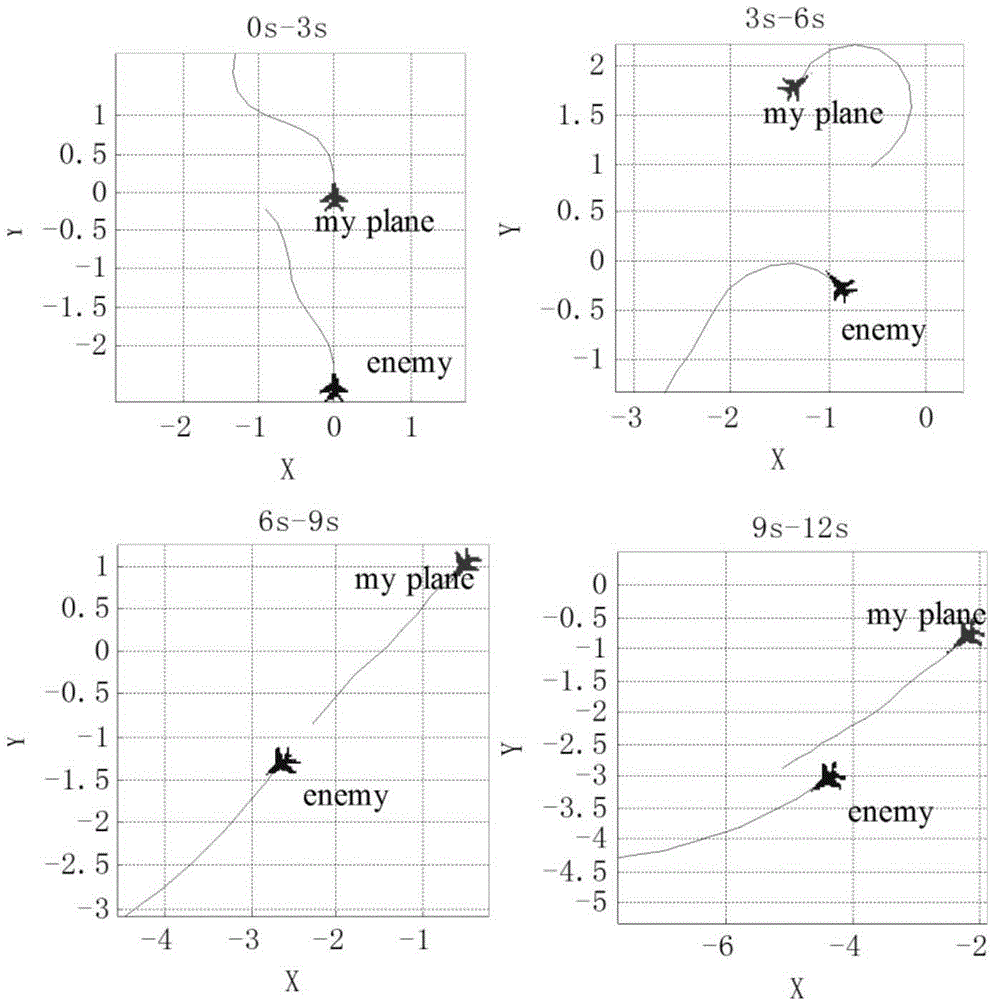
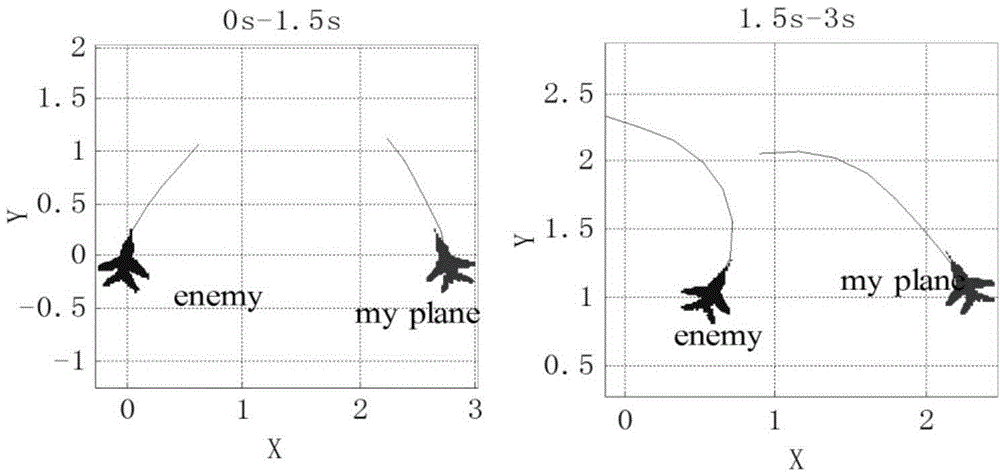
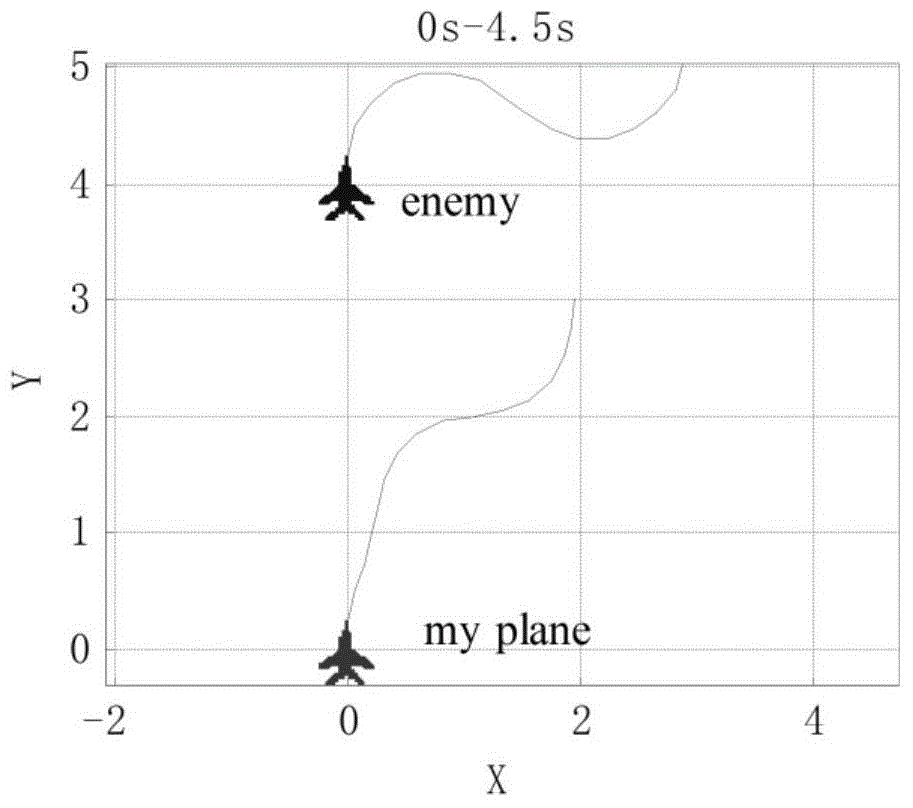
[0098] Step 101: Establish a combat simulation involving the red and blue aircraft. Among them, both warring parties adopt a traditional combat decision-making method, called the max-min method. Taking the red team as an example, the decision-making process of this method can be described as: choose an action that maximizes the immediate reward S(x) and minimizes the immediate reward of the blue team for any situation x. The blue side made the same decision. Sampling results such as Figure 5 shown.
[0099] Step 102: Record the combat trajectory generated by the combat simulation, and obtain a set of trajectory sampling points.
[0100] Step 2: Utility function fitting.
[0101] Step 201: Establish a feature set, as shown in Table 1.
[0102] Step 202: Perform utility function fitting, the process is as follows figure 2 shown.
[0103] Step 3: Make operational decisions.
[0104] Through the forward testing method, the final a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More