

Voiceprint identification method based on global change space and deep learning hybrid modeling
A global change and deep learning technology, applied in speech analysis, instruments, etc., can solve the problems of reducing the performance of voiceprint recognition methods, mismatching training and testing environments, etc., and achieve the effects of improving performance, making up for deficiencies, and strong robustness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
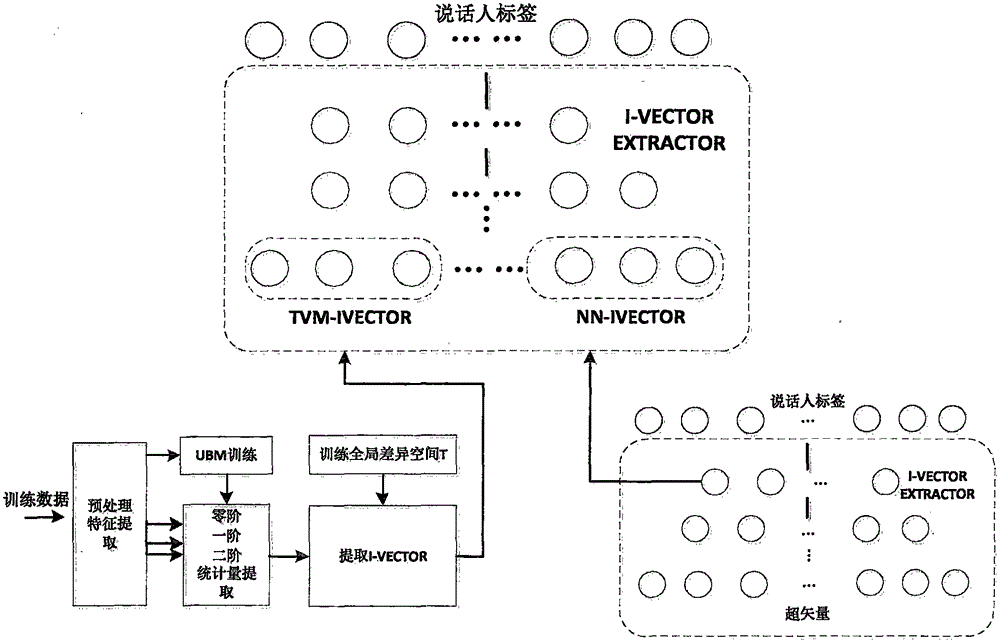
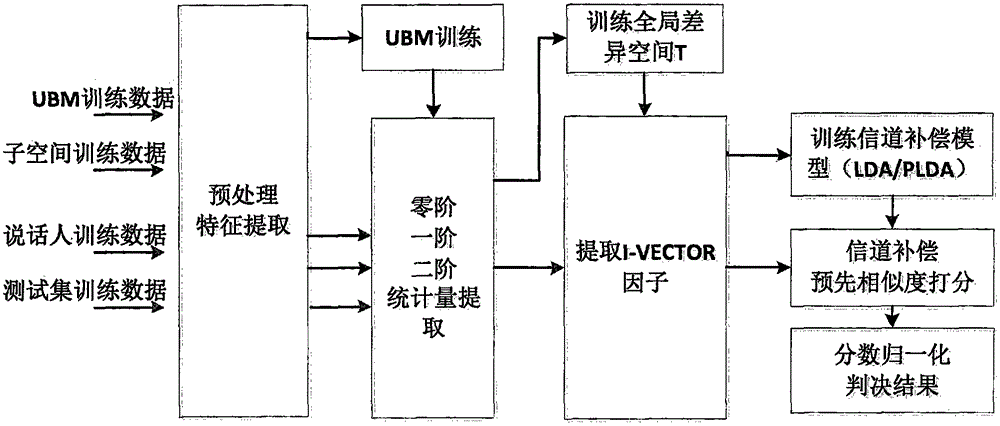
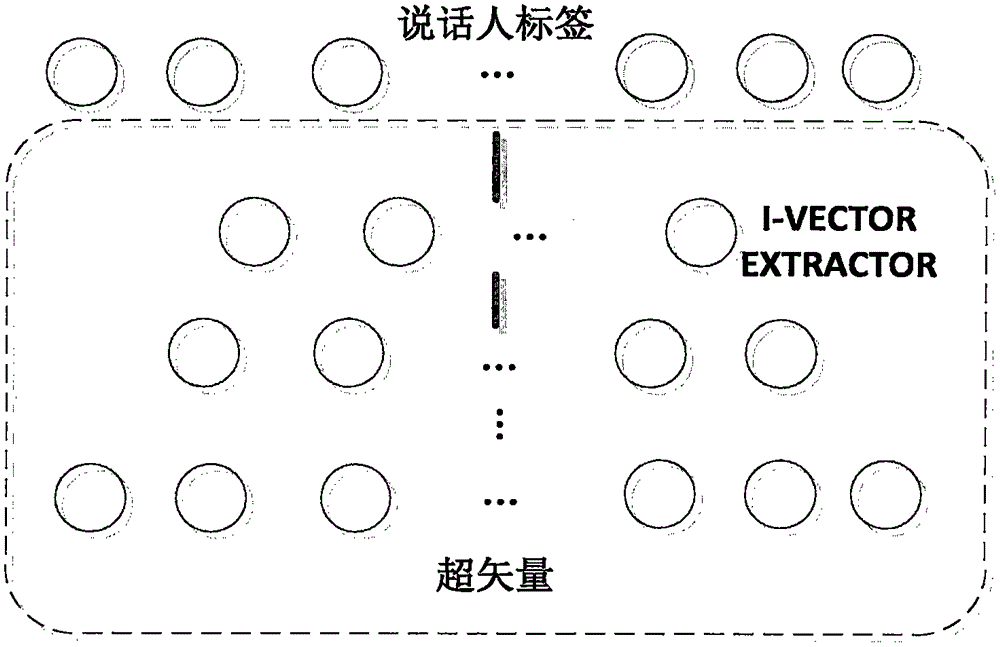
[0058] In step S100 , the original speech is obtained, features of Mel-frequency cepstral coefficients are extracted, endpoint detection is realized through short-term energy and short-term zero-crossing rate, and non-audio data in the original speech is eliminated to obtain speech segment data. Mel-frequency cepstral coefficient features are composed of 19-dimensional cepstrum features plus 1-dimensional energy features, and their first-order and second-order dynamic parameters, a total of 60-dimensional vectors.
[0059] The general background model for male and female voices is trained separately, and the general background model for male voices and the general background model for female voices are trained separately for the different characteristics of male and female voices. Since the general background model is used to describe the common characteristics of all speaker data, the number of mixtures of the general background model is relatively high, and 2048 dimensions ar...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More