Dual-sensor voice enhancement method based on statistics model and device
A statistical model and speech enhancement technology, applied in speech analysis, instruments, etc., can solve the problems of statistical characteristic interference, enhanced speech signal-to-noise ratio reduction, speech enhancement effect is not obvious, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
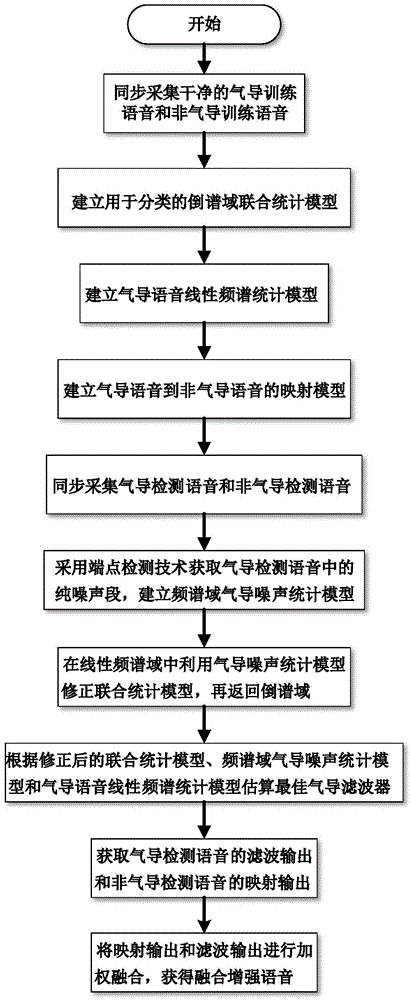
[0090] This embodiment discloses a dual-sensor speech enhancement method based on a statistical model, and the specific process steps refer to the appended figure 1 As shown, it can be known that the dual-sensor speech enhancement method includes the following process steps:
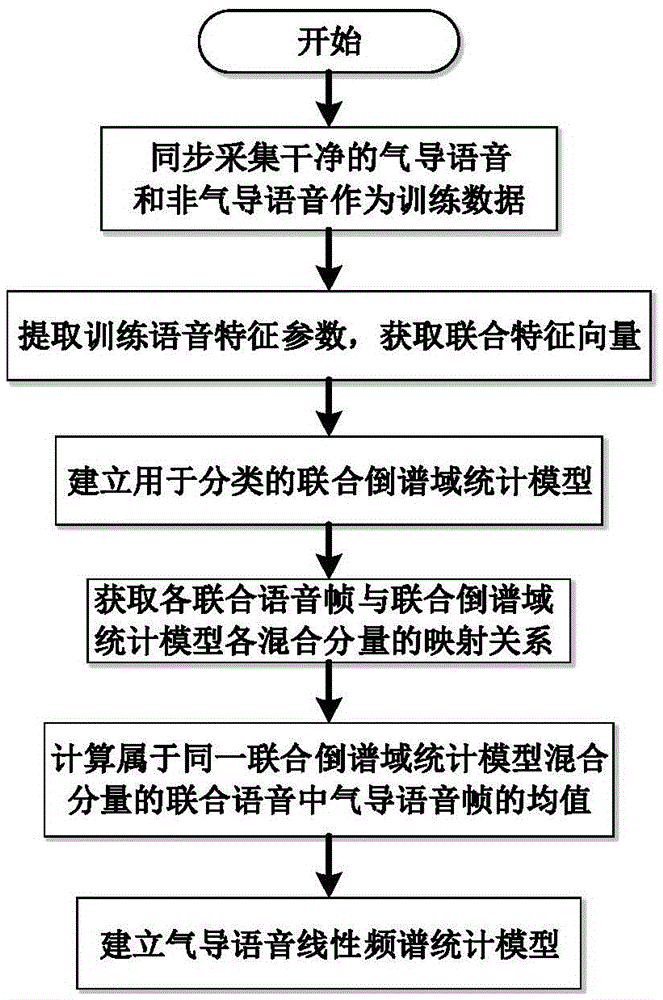
[0091] Step S1: Synchronously collect clean air conduction training speech and non-air conduction training speech, establish a joint statistical model for classification, and calculate the linear spectrum statistical model of air conduction speech corresponding to each classification, which can be further divided into the following step, the process is as figure 2 Shown:
[0092] Step S1.1: Synchronously collect clean air conduction training speech and non-air conduction training speech and divide them into frames, and extract the characteristic parameters of each frame of speech;
[0093] In the above embodiments, the voice receiving module is used to collect clean and synchronized air conduction tra...
Embodiment 2
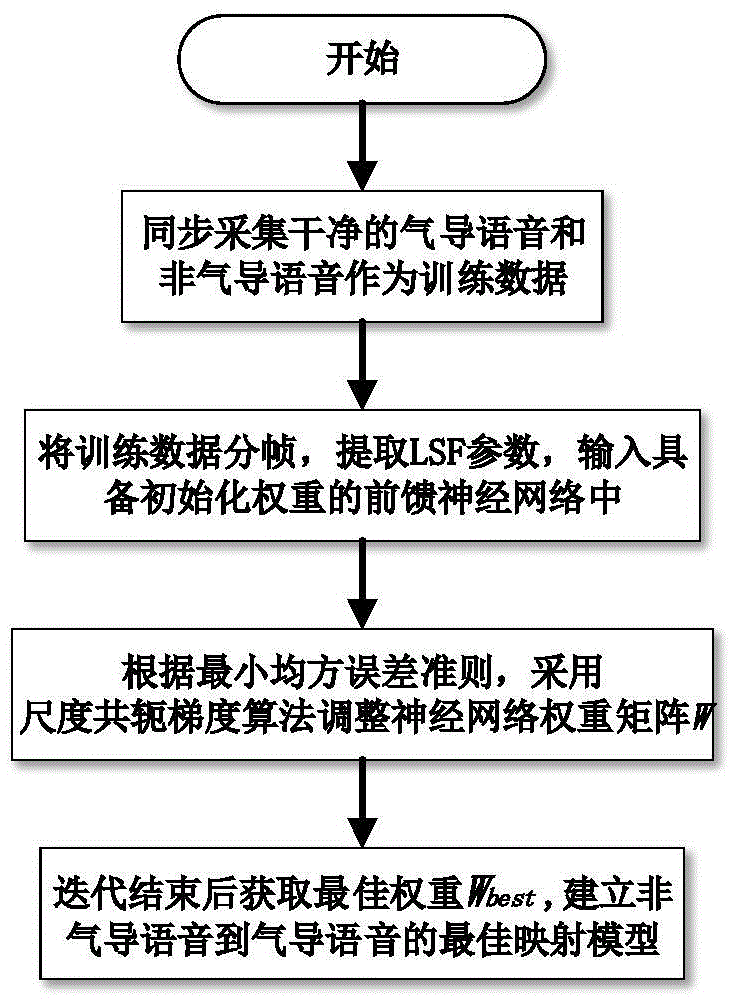
[0175] The second embodiment discloses a model-based dual-sensor speech enhancement device, which consists of a speech receiving module, a speech statistical model training module, an air conduction noise statistical model estimation module, an air conduction detection speech filter enhancement module, a speech mapping module, and a speech fusion Enhanced modules are composed together, and its structure is as follows figure 2 shown.
[0176] Among them, the voice receiving module is used to synchronously collect clean air conduction training voice and non-air conduction training voice;
[0177] Wherein, the speech statistical model training module is used to establish the joint statistical model and the air conduction speech linear spectrum statistical model;
[0178] Among them, the air conduction noise statistical model estimation module detects the endpoint of the air conduction detection voice, and then uses the pure noise segment of the air conduction detection voice to...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More