

Distributed crawler architecture based on Kafka and Quartz and implementation method thereof
A distributed, crawler technology, used in other database retrieval, program startup/switching, inter-program communication, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
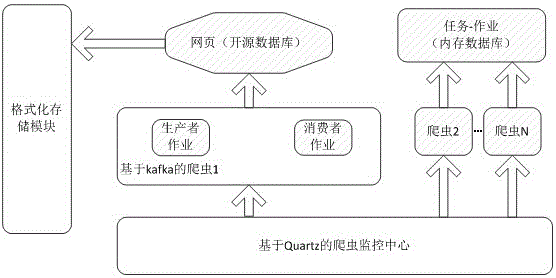
[0034]A distributed crawler architecture based on Kafka and Quartz of the present invention, the crawler architecture includes basic crawler components, URL storage queues, URL message distribution mechanism based on Kafka, crawler job scheduling mechanism and front-end console based on Quartz; basic crawler components It is an open source stand-alone crawler component, including page parsing to generate URL, URL filter and page crawling; page parsing and generating URL is responsible for extracting URL links from the current page. The URL filter is responsible for filtering the generated URL links according to the crawling rules to obtain URL links that meet the rules. Page crawling is responsible for crawling URL links that meet the crawling rules, and customizing the content of the page crawling. The URL storage queue adopts the memory database, and the memory database is used to store the URL message queue to be crawled and the URL that has been crawled, so as to realize t...
Embodiment 2
[0037] An implementation method of a distributed crawler architecture based on Kafka and Quartz, adopting a distributed crawler architecture based on Kafka and Quartz in Embodiment 1, comprising the following steps:
[0038] (1) Set the parameters of crawling entry, crawling rules, storage method of crawling results and scheduling rules through the page of the front-end console, and select the cluster nodes to be deployed for deployment;
[0039] (2) According to the Quartz-based job scheduling mechanism, the producer job calls the basic crawler component to extract the crawl URL link according to the crawler entry, and deduplicate and store it in the queue to be crawled;
[0040] (3) The consumer job of each node calls the basic crawler component according to the Quartz-based job scheduling mechanism, obtains the URL link message distributed to the node by the Kafka-based message distribution mechanism, parses and crawls the URL link, and store the results in the system;
[...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More