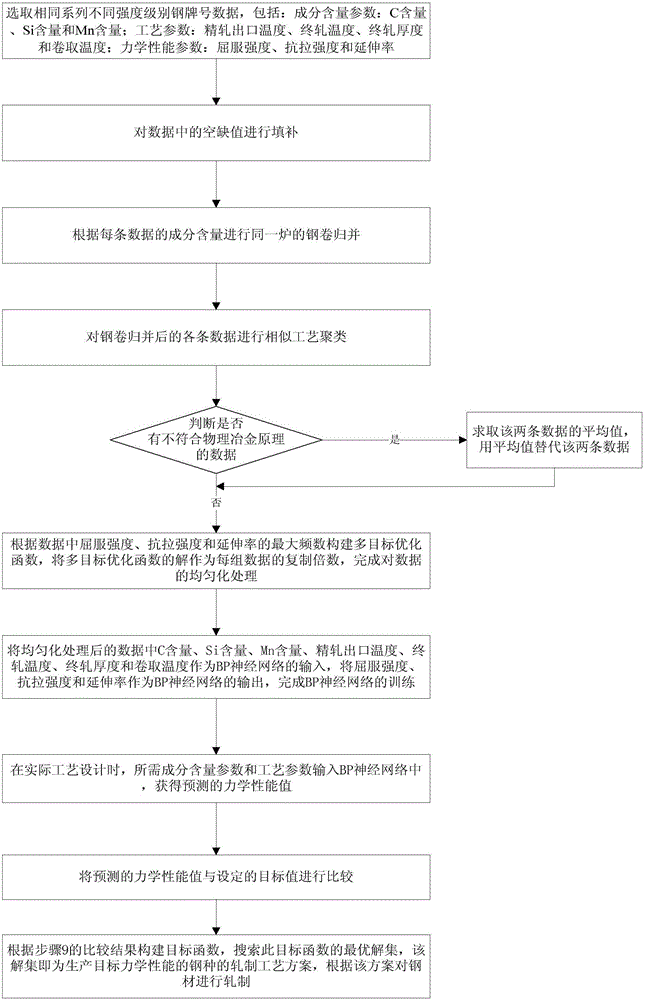
[0002] In the industrial production of C-Mn steel, a large amount of production data will be collected, and technicians can use the information contained in these data to establish a mechanical
performance prediction model, but if the original production data is directly applied without
processing, many problems will arise
First of all, there is a large amount of redundant data in the original production data. Too much redundant data will increase the amount of modeling calculations, and at the same time lead to insufficient regularity; under normal circumstances, each furnace of
molten steel can usually produce several steel coils , when testing the mechanical properties, several samples will be
cut from each steel coil; if these steel coils are used to produce plates and strips of the same thickness specification, and the same rolling process is adopted, then each furnace of steel
ingot will correspond to multiple sets of data ; Therefore, the information contained in these data is the same or similar, and the application of a large number of data containing the same information in
data modeling will increase the amount of calculation of modeling; because the process standard of tapping marks is formulated in the form of intervals , the actual process is constrained by the capacity of the
production line equipment, so the collected data are distributed in a discrete state
The small fluctuations in the numerical values of process parameters are within the allowable range of errors in actual production operations. These data can also be regarded as data containing the same or similar information, which will also increase the amount of modeling calculations
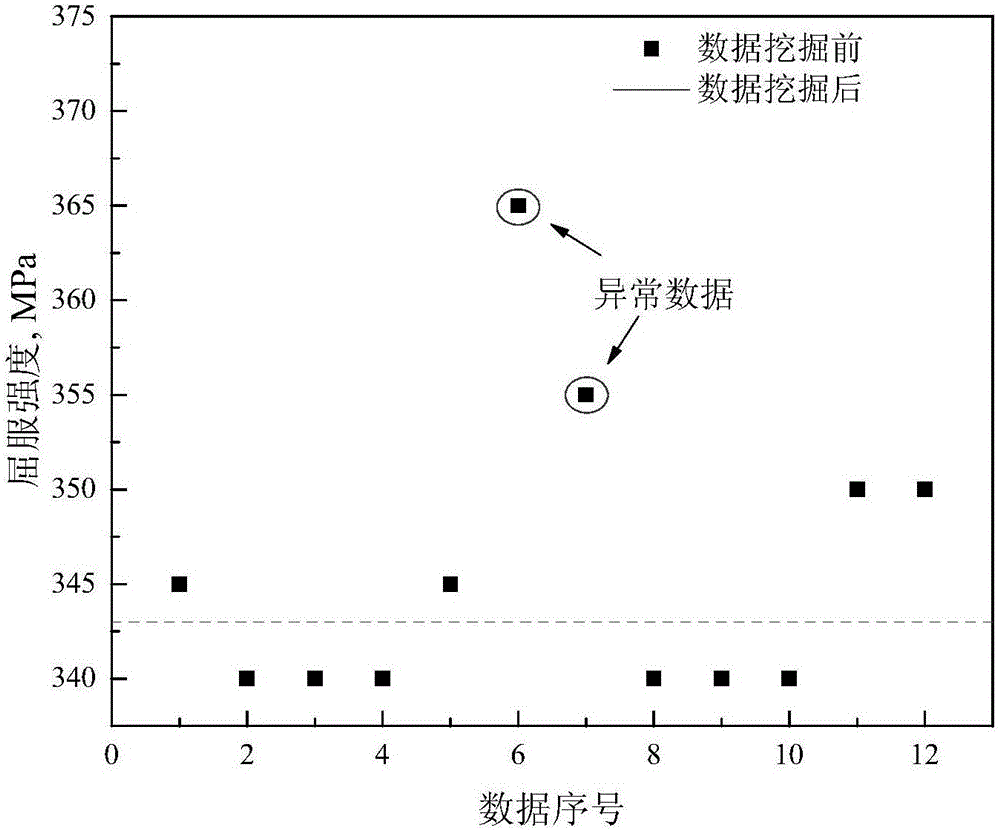
Secondly, due to detection errors and human intervention in the industrial
system, if the
raw data collected by the
production line is directly used for modeling without
processing, the analysis results are prone to distortions that deviate from the facts; in addition, industrial data is usually unevenly distributed , such data cannot reflect objective and comprehensive information, resulting in the characteristics of the established model tending to the characteristics of the region in the
data set; for example, when using a neural network to establish a mechanical
performance model ( Figure 5 ), analyze the change curve of yield strength with C content, when the C content is higher than 0.1%, there will be a phenomenon that the yield strength decreases with the increase of C content; similarly, when analyzing the final rolling thickness and coiling temperature There will also be phenomena that violate the laws of
physical metallurgy; this is because the
original data is not uniformly distributed, the
signal-to-
noise ratio is low, and there are too many artificial feedback adjustments in the production that cause the data laws to be buried; therefore, before applying
neural network modeling, it is necessary A series of methods have been developed to mine the reasonable physical and metallurgical relationship contained in the
big data of C-Mn steel industry; only by using the data of the correct composition and process performance correspondence can a model reflecting the correct physical and metallurgical relationship be established, which will help in the future The correct process is obtained in the reverse optimization calculation of the target value of the mechanical properties; therefore, the accurate mining of the relationship between the composition and process properties contained in the big data of C-Mn steel production is an important basis for the
process optimization of mechanical properties
[0003] By searching the
database of the State
Intellectual Property Office and the SOOPAT
database, there are currently no relevant patents published for the mining method of C-Mn steel industrial big data; the current literature modeling of steel production data mainly uses a single steel type for modeling, because the single steel Due to the singleness of the production process, the data distribution is concentrated on the set target value of the steel rolling process, so the selected data cannot include comprehensive
process information, resulting in poor applicability of the model; the
data mining methods in the literature are also too simple, usually only include There are two steps of data loading and data cleaning, and the data cleaning method is relatively monotonous, without considering the process characteristics of the actual production of C-Mn, which often cannot meet the needs of users, resulting in unsatisfactory results of
data mining, which directly affects the accuracy of modeling and validity



 Login to View More
Login to View More  Login to View More
Login to View More