Data query method and device based on big data environment
A big data and environmental technology, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., to achieve the effect of expanding capacity, making up for the inability to communicate directly, and improving query efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

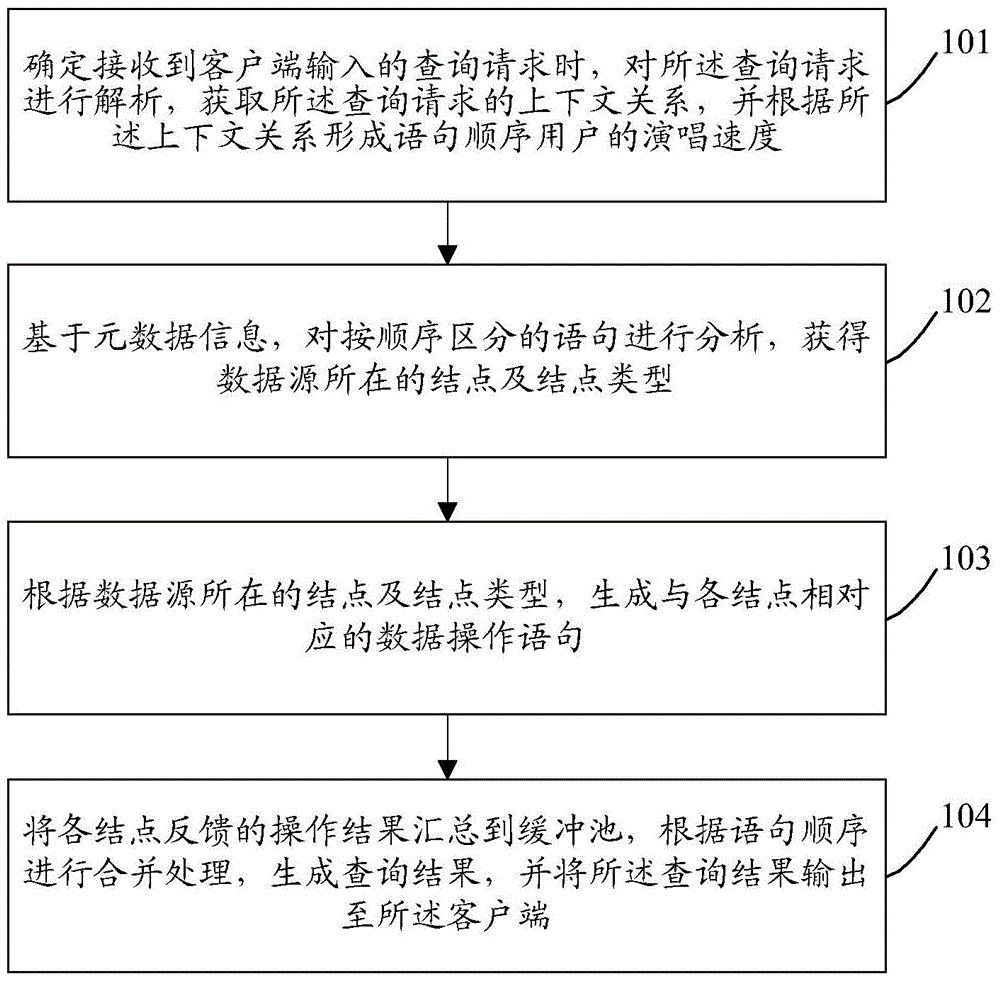
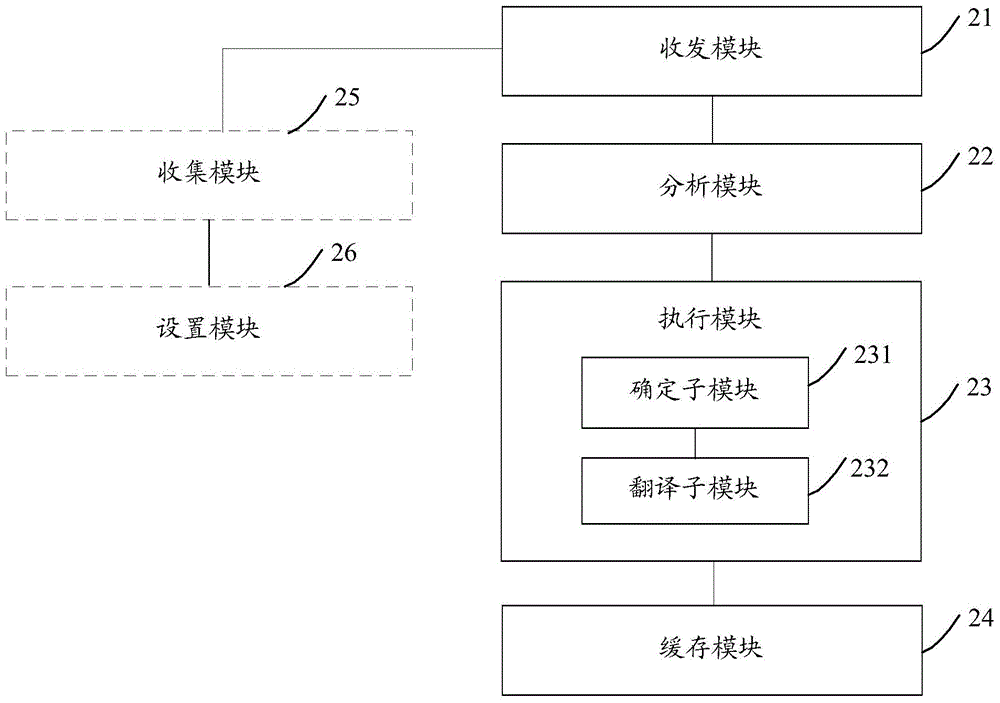
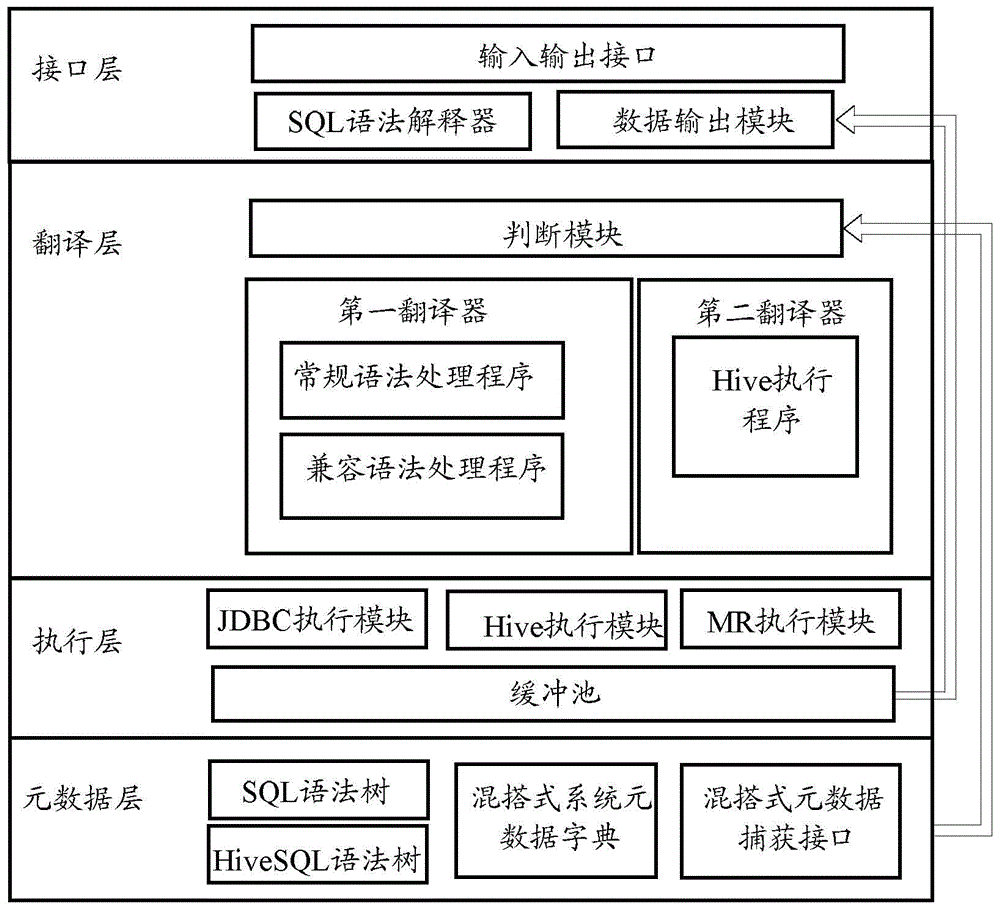
Examples
example 1
[0191] Example 1: Realize the left outer connection (ie left outer connection)
[0192] SELECT count(F. title)
[0193] FROM
[0194] Hbase.FactTable F LEFT JOIN DB2.Dim D
[0195] ON F.cid=D.cid
[0196] Where D.category_name='bingo',
[0197] Explanation: Extract the number of records with category_name='bingo' in the FactTable of Hbase, but there is no category_name information in the FactTable, which is stored in the Dim table of the DB2 database; the title is stored in the FactTable of Hbase, and the category_name is stored in DB2 On the Dim table of the database, there are about 100 million rows of data in the Fact table, 1 million records in the Dim table, and only 1,000 records with category_name='bingo'.
[0198] In the prior art, there are two general processing methods, the first method is to gather FactTable and DimTable together, and then do processing; the second method is to manually obtain the record number of category_name='bingo' on DB2, ...
example 2
[0200] Example 2: Realize inserting data into the database table
[0201] INSERT INTO
[0202] DB2.FactTable1000(title, category_name)
[0203] VALUES(
[0204] SELECT F.title,D.category_name
[0205] FROM
[0206] Hbase.FactTable1F LEFT JOIN DB2.Dim D
[0207] ON F.cid=D.cid
[0208] Where D.cid>1000
[0209] )
[0210] Description: Extract the title and category_name of cid>1000 from the FactTable of HBase and the category_name of the DimTable and store them in the DB2 database for daily query.
[0211] Using the method of the present invention, the query process is realized through the unified interface. The unified interface obtains the context relationship by explaining the SQL, and learns that it first needs to go to the DB2 database with cid>1000, and then finds the matching record on the HBase through the cid to obtain the record. After that, return to the buffer pool, in the buffer pool, merge the data, and then return to the client. T...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com