Method for extracting core content of webpage based on text-tag density
A technology of core content and extraction method, which is applied in the Internet and communication fields, can solve problems such as poor versatility, improve accuracy, improve efficiency and accuracy, and achieve simple effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0040] The present invention will be described in detail below with reference to the drawings and embodiments.
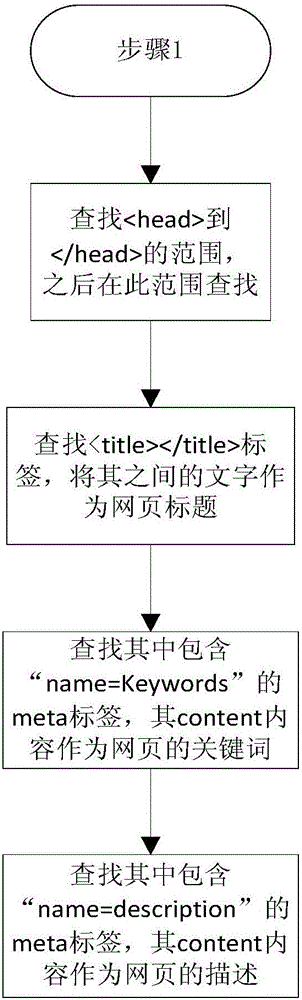
[0041] This invention takes the source code of the webpage as input, and outputs the core text of the webpage including the title, keywords, description, and core content, and its focus is on the core content of the webpage of acquisition.
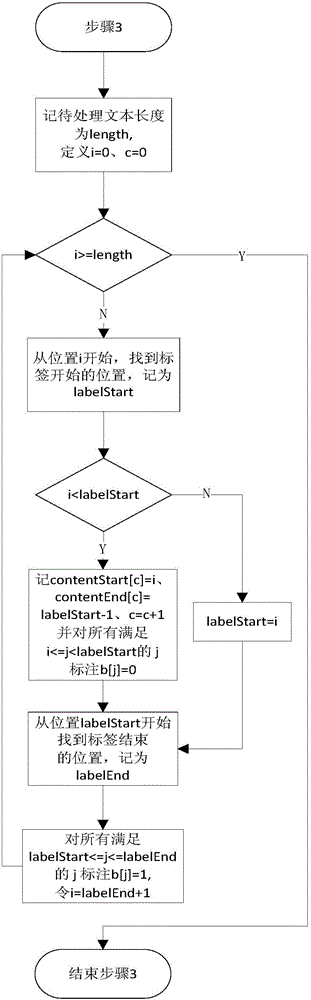
[0042] as follows As shown in Figure 1, the processing process of the present invention includes four stages: webpage source code preprocessing, webpage core content range estimation, core content boundary determination, and deletion of remaining tags.
[0043] The present invention is specifically realized through the following technical solutions:
[0044] 1. Web page source code Preprocessing stage
[0045] The preprocessing stage needs to extract the core elements of the webpage such as the title, keywords, and description from the original webpage text, and delete the text part of the webpage that is easy to interfere The tag for extr...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More