

Correlativity feature-containing simulative stream big data generation method for system test
A technology for data generation and system testing, applied in electrical digital data processing, software testing/debugging, error detection/correction, etc., to achieve the effect of increasing parallelism, increasing efficiency, and enriching fields
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

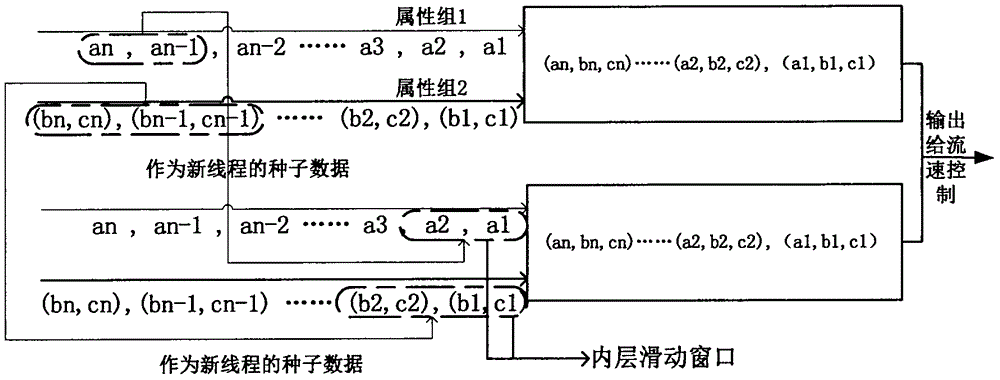

Examples
Embodiment Construction
[0017] The present invention will be described in detail below in conjunction with the accompanying drawings and specific examples.
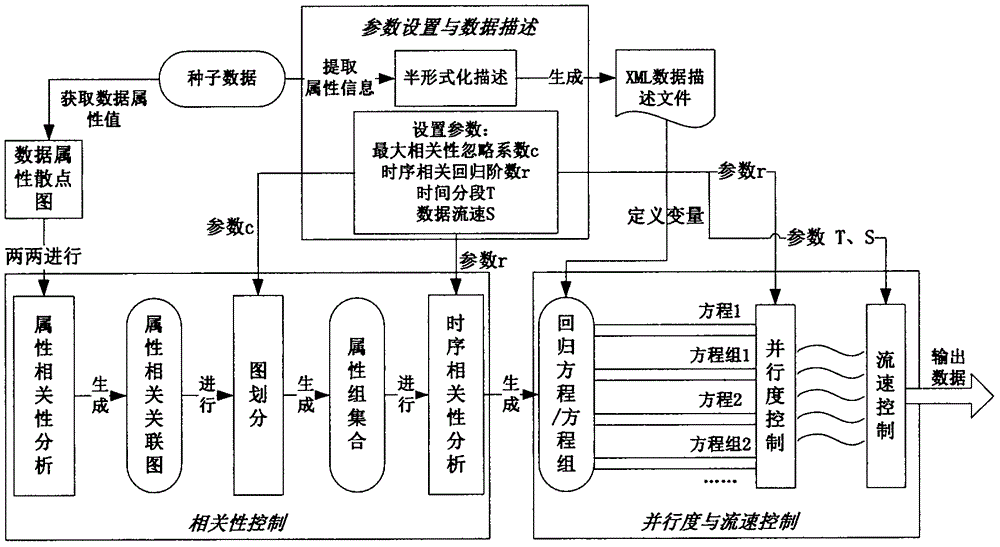
[0018] as attached figure 1 As shown, the method consists of three parts: parameter setting and data description, correlation control, parallelism and flow rate control.
[0019] The parameter setting and data description module, after obtaining the seed data, first processes the seed data to extract the attributes of the data, including the number of attributes, attribute types, and attribute value ranges. For string type data, its maximum length needs to be calculated. Generate an xml file; at the same time, the user needs to define four parameters, the maximum correlation ignore coefficient c, the time series correlation regression order r, the time segment T, and the segmental flow rate S.
[0020] Next, data correlation analysis is carried out, and the specific implementation process is as follows:
[0021] Step 1: Perform MIC calculation...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More