

Wiki semantic matching-based document classification method and system
A document classification and semantic matching technology, applied in the Internet field, can solve the problems of low efficiency and inaccuracy of document classification technology
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
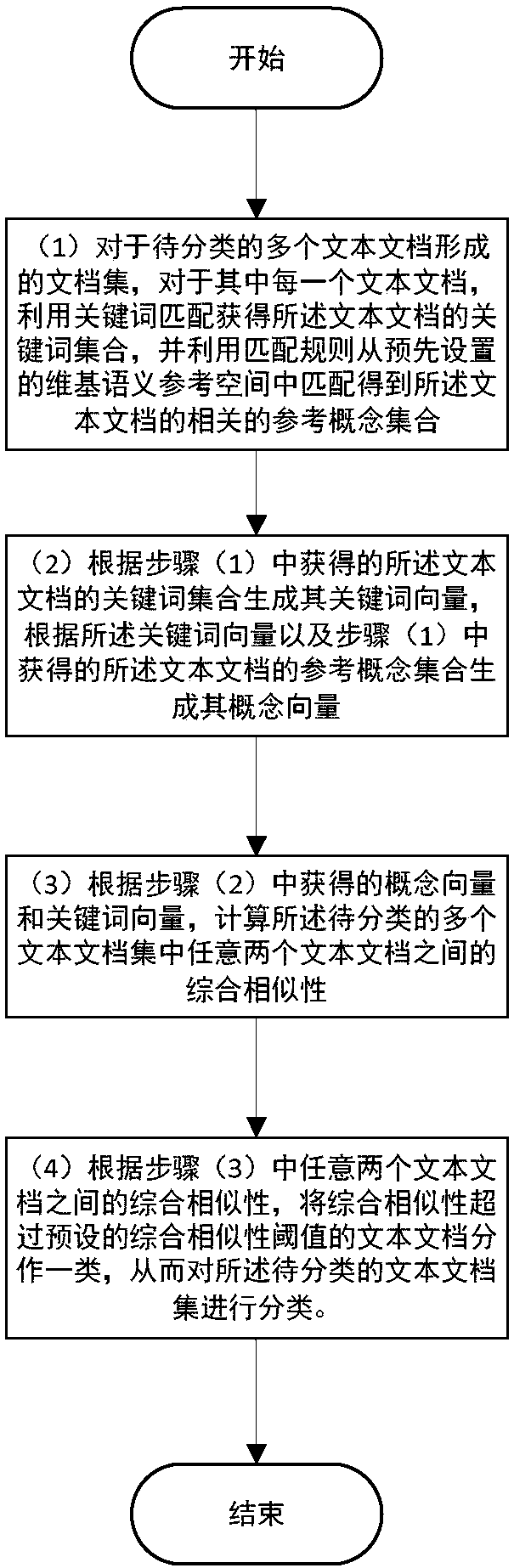
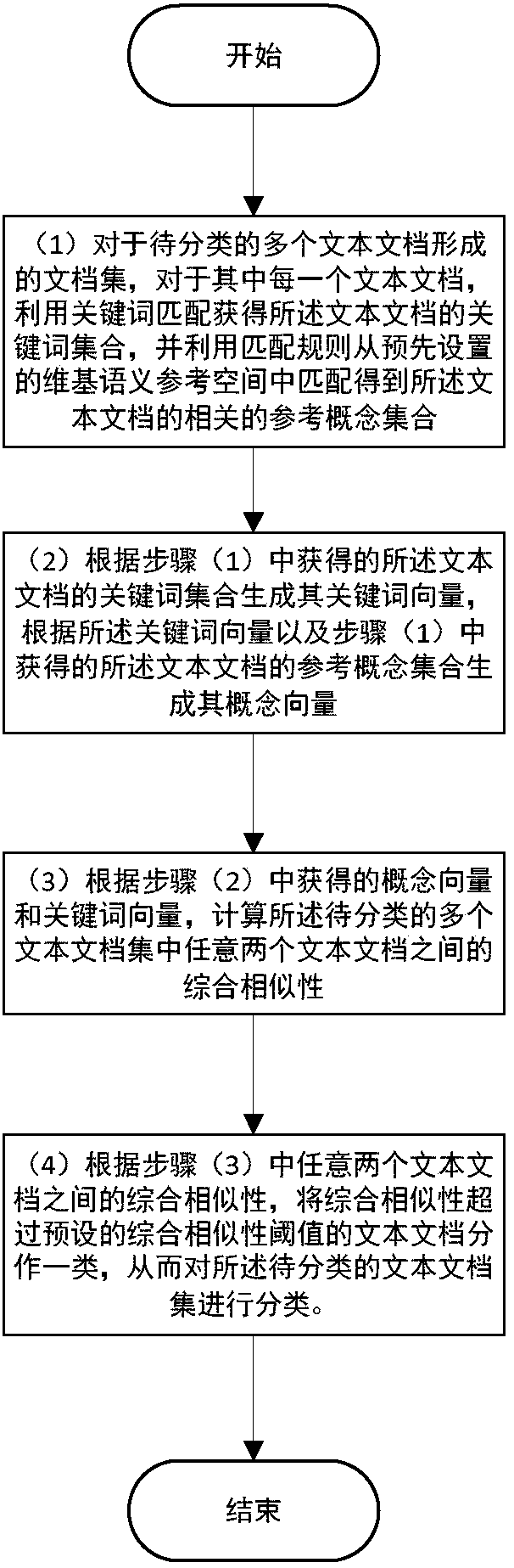
[0179] A document classification method based on wiki semantic matching, pre-constructed wiki semantic reference space
[0180] Extract 100,000 conceptual entities from the Wikipedia database, and preprocess the concepts according to the following steps:
[0181] A. Word segmentation: Use the NLTK tokenizer (www.nltk.org) to divide each concept Express as a set of independent words, and lowercase each word;
[0182] B. Remove stop words: remove stop words from the set of independent words corresponding to each concept in step A, including prepositions, pronouns, and articles, so that each concept Expressed as a set of words with independent meaning;
[0183] C. Stemization: Use the famous Snowball framework (snowall.tartarus.org / texts / introduction.html) to convert each concept obtained in step B Each word in the corresponding independent set of words with meaning is transformed into its stem, thereby converting each concept Expressed as a set of keywords, it can be w...
Embodiment 2
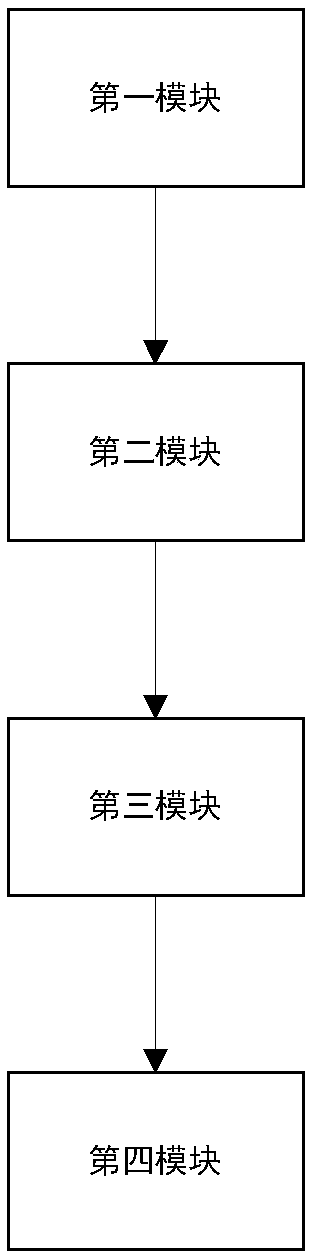
[0240] A document classification system based on wiki semantic matching, including:
[0241] The first module, which has the wiki semantic reference space built in, is used to obtain the text document set formed by the text documents to be classified and for each of these text documents Use keyword matching to obtain the keyword set of the text document, and use matching rules to match the related reference concept set of the text document from the Wiki semantic reference space; The corresponding keyword set and reference concept set are submitted to the second module.
[0242] The first module includes a keyword matching submodule and a reference concept matching submodule.
[0243] The keyword matching submodule is used to match a given text document Obtain its keyword collection, including:
[0244] A word segmentation component for dividing a given text document into Represented as an independent word set, submitted to the stop word removal component;
[0245] T...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More